

People have the exceptional means to absorb an incredible quantity of info (estimated to be ~1010 bits/s getting into the retina) and selectively attend to a couple task-relevant and fascinating areas for additional processing (e.g., reminiscence, comprehension, motion). Modeling human attention (the end result of which is usually known as a saliency mannequin) has due to this fact been of curiosity throughout the fields of neuroscience, psychology, human-computer interplay (HCI) and laptop imaginative and prescient. The means to foretell which areas are prone to appeal to attention has quite a few essential functions in areas like graphics, pictures, picture compression and processing, and the measurement of visible high quality.
We’ve beforehand mentioned the likelihood of accelerating eye motion analysis utilizing machine studying and smartphone-based gaze estimation, which earlier required specialised {hardware} costing as much as $30,000 per unit. Related analysis contains “Look to Speak”, which helps customers with accessibility wants (e.g., individuals with ALS) to speak with their eyes, and the just lately revealed “Differentially private heatmaps” method to compute heatmaps, like these for attention, whereas defending customers’ privateness.
In this weblog, we current two papers (one from CVPR 2022, and one simply accepted to CVPR 2023) that spotlight our current analysis within the space of human attention modeling: “Deep Saliency Prior for Reducing Visual Distraction” and “Learning from Unique Perspectives: User-aware Saliency Modeling”, along with current analysis on saliency pushed progressive loading for picture compression (1, 2). We showcase how predictive models of human attention can allow delightful user experiences akin to picture modifying to reduce visible muddle, distraction or artifacts, picture compression for sooner loading of webpages or apps, and guiding ML models in the direction of extra intuitive human-like interpretation and mannequin efficiency. We deal with picture modifying and picture compression, and focus on current advances in modeling within the context of these functions.
Attention-guided picture modifying
Human attention models normally take a picture as enter (e.g., a pure picture or a screenshot of a webpage), and predict a heatmap as output. The predicted heatmap on the picture is evaluated in opposition to ground-truth attention information, that are sometimes collected by a watch tracker or approximated via mouse hovering/clicking. Previous models leveraged handcrafted options for visible clues, like coloration/brightness distinction, edges, and form, whereas more moderen approaches robotically study discriminative options based mostly on deep neural networks, from convolutional and recurrent neural networks to more moderen imaginative and prescient transformer networks.
In “Deep Saliency Prior for Reducing Visual Distraction” (extra info on this mission web site), we leverage deep saliency models for dramatic but visually life like edits, which may considerably change an observer’s attention to totally different picture areas. For instance, eradicating distracting objects within the background can cut back muddle in photographs, resulting in elevated user satisfaction. Similarly, in video conferencing, lowering muddle within the background could enhance deal with the primary speaker (instance demo right here).
To discover what varieties of modifying results might be achieved and the way these have an effect on viewers’ attention, we developed an optimization framework for guiding visible attention in pictures utilizing a differentiable, predictive saliency mannequin. Our technique employs a state-of-the-art deep saliency mannequin. Given an enter picture and a binary masks representing the distractor areas, pixels inside the masks will likely be edited beneath the steerage of the predictive saliency mannequin such that the saliency inside the masked area is lowered. To be sure the edited picture is pure and life like, we fastidiously select 4 picture modifying operators: two normal picture modifying operations, particularly recolorization and picture warping (shift); and two discovered operators (we don’t outline the modifying operation explicitly), particularly a multi-layer convolution filter, and a generative mannequin (GAN).
With these operators, our framework can produce a range of highly effective results, with examples within the determine beneath, together with recoloring, inpainting, camouflage, object modifying or insertion, and facial attribute modifying. Importantly, all these results are pushed solely by the only, pre-trained saliency mannequin, with none further supervision or coaching. Note that our aim is to not compete with devoted strategies for producing every impact, however quite to show how a number of modifying operations might be guided by the data embedded inside deep saliency models.
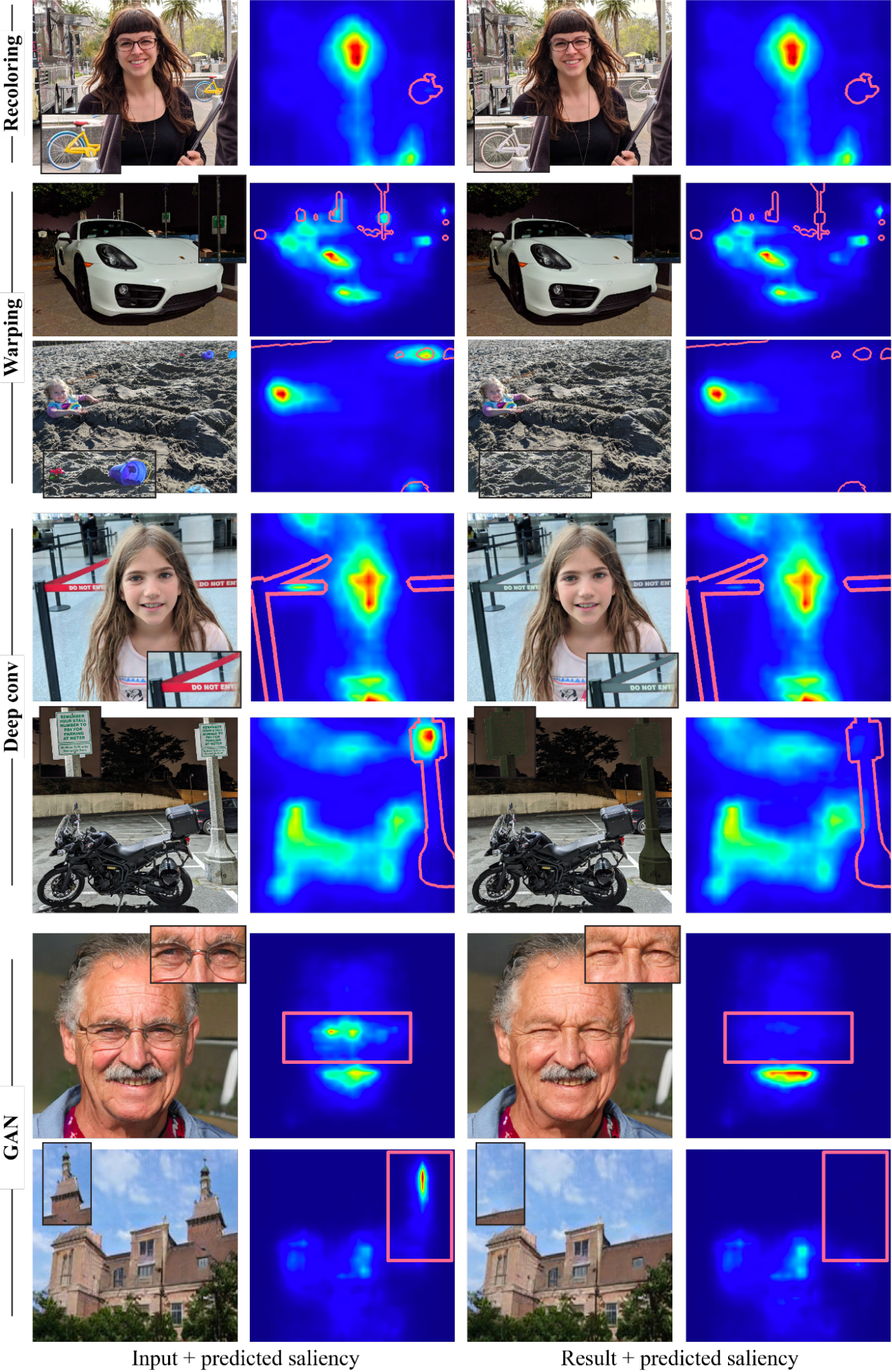 |
| Examples of lowering visible distractions, guided by the saliency mannequin with a number of operators. The distractor area is marked on prime of the saliency map (pink border) in every instance. |
Enriching experiences with user-aware saliency modeling
Prior analysis assumes a single saliency mannequin for the entire inhabitants. However, human attention varies between people — whereas the detection of salient clues is pretty constant, their order, interpretation, and gaze distributions can differ considerably. This provides alternatives to create personalised user experiences for people or teams. In “Learning from Unique Perspectives: User-aware Saliency Modeling”, we introduce a user-aware saliency mannequin, the primary that may predict attention for one user, a bunch of customers, and the final inhabitants, with a single mannequin.
As proven within the determine beneath, core to the mannequin is the mixture of every participant’s visible preferences with a per-user attention map and adaptive user masks. This requires per-user attention annotations to be accessible within the coaching information, e.g., the OSIE cellular gaze dataset for pure pictures; FiWI and WebSaliency datasets for internet pages. Instead of predicting a single saliency map representing attention of all customers, this mannequin predicts per-user attention maps to encode people’ attention patterns. Further, the mannequin adopts a user masks (a binary vector with the scale equal to the quantity of contributors) to point the presence of contributors within the present pattern, which makes it potential to pick out a bunch of contributors and mix their preferences right into a single heatmap.
 |
| An overview of the user conscious saliency mannequin framework. The instance picture is from OSIE picture set. |
During inference, the user masks permits making predictions for any mixture of contributors. In the next determine, the primary two rows are attention predictions for 2 totally different teams of contributors (with three individuals in every group) on a picture. A standard attention prediction mannequin will predict similar attention heatmaps. Our mannequin can distinguish the 2 teams (e.g., the second group pays much less attention to the face and extra attention to the meals than the primary). Similarly, the final two rows are predictions on a webpage for 2 distinctive contributors, with our mannequin displaying totally different preferences (e.g., the second participant pays extra attention to the left area than the primary).
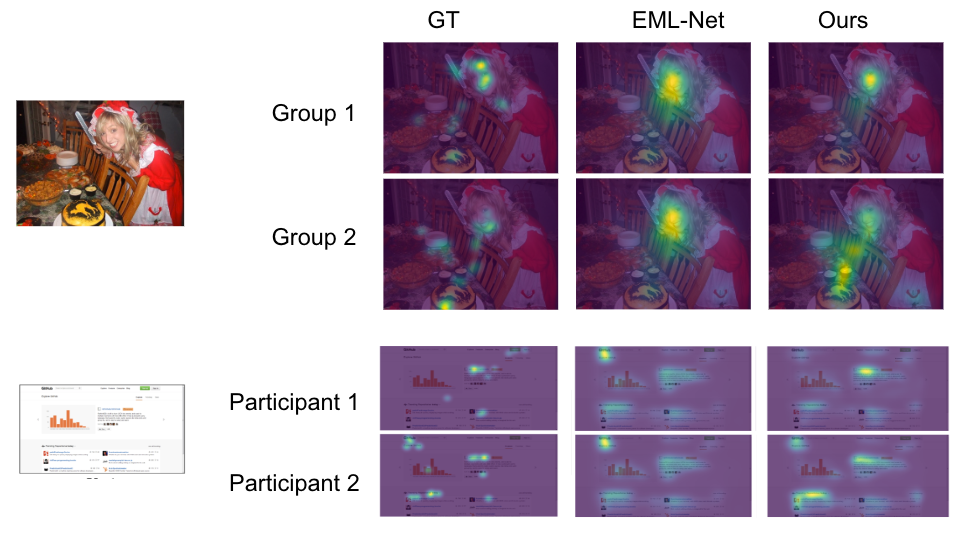 |
| Predicted attention vs. floor fact (GT). EML-Net: predictions from a state-of-the-art mannequin, which can have the identical predictions for the 2 contributors/teams. Ours: predictions from our proposed user conscious saliency mannequin, which may predict the distinctive desire of every participant/group accurately. The first picture is from OSIE picture set, and the second is from FiWI. |
Progressive picture decoding centered on salient options
Besides picture modifying, human attention models can even enhance customers’ shopping expertise. One of essentially the most irritating and annoying user experiences whereas shopping is ready for internet pages with pictures to load, particularly in circumstances with low community connectivity. One approach to enhance the user expertise in such instances is with progressive decoding of pictures, which decodes and shows more and more higher-resolution picture sections as information are downloaded, till the full-resolution picture is prepared. Progressive decoding normally proceeds in a sequential order (e.g., left to proper, prime to backside). With a predictive attention mannequin (1, 2), we will as an alternative decode pictures based mostly on saliency, making it potential to ship the info essential to show particulars of essentially the most salient areas first. For instance, in a portrait, bytes for the face might be prioritized over these for the out-of-focus background. Consequently, customers understand higher picture high quality earlier and expertise considerably lowered wait instances. More particulars might be present in our open supply weblog posts (put up 1, put up 2). Thus, predictive attention models might help with picture compression and sooner loading of internet pages with pictures, enhance rendering for big pictures and streaming/VR functions.
Conclusion
We’ve proven how predictive models of human attention can allow delightful user experiences via functions akin to picture modifying that may cut back muddle, distractions or artifacts in pictures or photographs for customers, and progressive picture decoding that may drastically cut back the perceived ready time for customers whereas pictures are totally rendered. Our user-aware saliency mannequin can additional personalize the above functions for particular person customers or teams, enabling richer and extra distinctive experiences.
Another fascinating course for predictive attention models is whether or not they might help enhance robustness of laptop imaginative and prescient models in duties akin to object classification or detection. For instance, in “Teacher-generated spatial-attention labels boost robustness and accuracy of contrastive models”, we present {that a} predictive human attention mannequin can information contrastive studying models to realize higher illustration and enhance the accuracy/robustness of classification duties (on the PictureNet and PictureNet-C datasets). Further analysis on this course might allow functions akin to utilizing radiologist’s attention on medical pictures to enhance well being screening or prognosis, or utilizing human attention in advanced driving eventualities to information autonomous driving methods.
Acknowledgements
This work concerned collaborative efforts from a multidisciplinary crew of software program engineers, researchers, and cross-functional contributors. We’d prefer to thank all of the co-authors of the papers/analysis, together with Kfir Aberman, Gamaleldin F. Elsayed, Moritz Firsching, Shi Chen, Nachiappan Valliappan, Yushi Yao, Chang Ye, Yossi Gandelsman, Inbar Mosseri, David E. Jacobes, Yael Pritch, Shaolei Shen, and Xinyu Ye. We additionally wish to thank crew members Oscar Ramirez, Venky Ramachandran and Tim Fujita for his or her assist. Finally, we thank Vidhya Navalpakkam for her technical management in initiating and overseeing this physique of work.