

In latest years, LMMs have quickly expanded, leveraging CLIP as a foundational imaginative and prescient encoder for sturdy visible representations and LLMs as versatile instruments for reasoning throughout numerous modalities. However, whereas LLMs have grown to over 100 billion parameters, the imaginative and prescient fashions they depend on should be larger, hindering their potential. Scaling up contrastive language-image pretraining (CLIP) is important to reinforce each imaginative and prescient and multimodal fashions, bridging the hole and enabling more practical dealing with of various knowledge sorts.
Researchers from the Beijing Academy of Artificial Intelligence and Tsinghua University have unveiled EVA-CLIP-18B, the most important open-source CLIP mannequin but, boasting 18 billion parameters. Despite coaching on simply 6 billion samples, it achieves a powerful 80.7% zero-shot top-1 accuracy throughout 27 picture classification benchmarks, surpassing prior fashions like EVA-CLIP. Notably, this development is achieved with a modest dataset of two billion image-text pairs, brazenly out there and smaller than these used in different fashions. EVA-CLIP-18B showcases the potential of EVA-style weak-to-strong visible mannequin scaling, with hopes of fostering additional analysis in imaginative and prescient and multimodal basis fashions.
EVA-CLIP-18B is the most important and strongest open-source CLIP mannequin, with 18 billion parameters. It outperforms its predecessor EVA-CLIP (5 billion parameters) and different open-source CLIP fashions by a big margin in phrases of zero-shot top-1 accuracy on 27 picture classification benchmarks. The ideas of EVA and EVA-CLIP information the scaling-up process of EVA-CLIP-18B. The EVA philosophy follows a weak-to-strong paradigm, the place a small EVA-CLIP mannequin serves because the imaginative and prescient encoder initialization for a bigger EVA-CLIP mannequin. This iterative scaling course of stabilizes and accelerates the coaching of bigger fashions.
EVA-CLIP-18B, an 18-billion-parameter CLIP mannequin, is educated on a 2 billion image-text pairs dataset from LAION-2B and COYO-700M. Following the EVA and EVA-CLIP ideas, it employs a weak-to-strong paradigm, the place a smaller EVA-CLIP mannequin initializes a bigger one, stabilizing and expediting coaching. Evaluation throughout 33 datasets, together with picture and video classification and image-text retrieval, demonstrates its efficacy. The scaling course of entails distilling data from a small EVA-CLIP mannequin to a bigger EVA-CLIP, with the coaching dataset principally mounted to showcase the effectiveness of the scaling philosophy. Notably, the strategy yields sustained efficiency features, exemplifying the effectiveness of progressive weak-to-strong scaling.
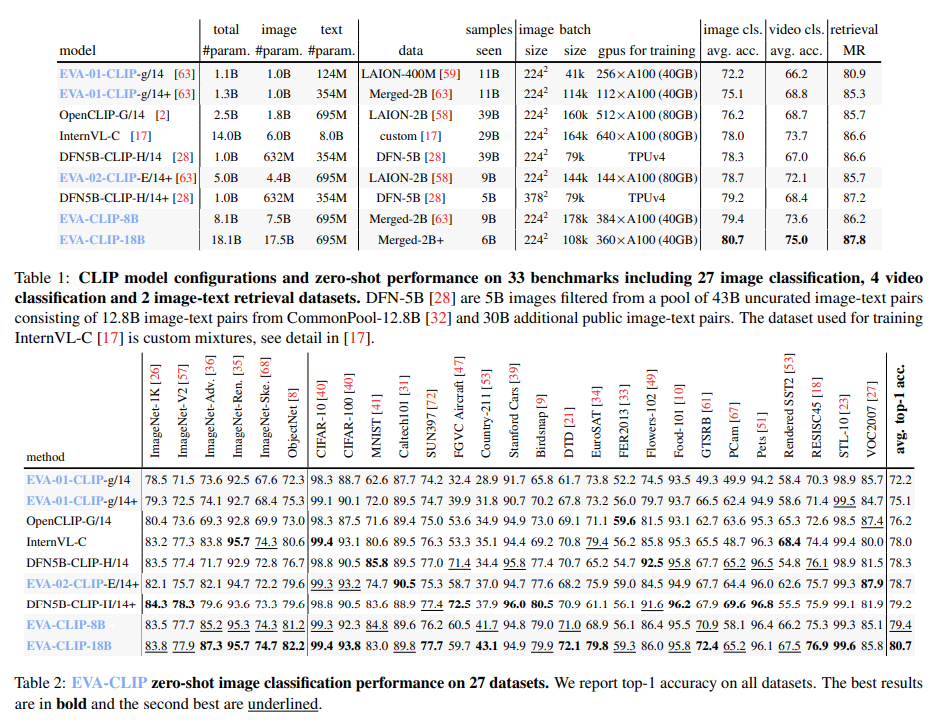
EVA-CLIP-18B, boasting 18 billion parameters, showcases excellent efficiency throughout numerous image-related duties. It achieves a powerful 80.7% zero-shot top-1 accuracy throughout 27 picture classification benchmarks, surpassing its predecessor and different CLIP fashions by a major margin. Moreover, linear probing on ImageNet-1K outperforms opponents like InternVL-C with a mean top-1 accuracy of 88.9. Zero-shot image-text retrieval on Flickr30K and COCO datasets achieves a mean recall of 87.8, considerably surpassing opponents. EVA-CLIP-18B reveals robustness throughout completely different ImageNet variants, demonstrating its versatility and excessive efficiency throughout 33 broadly used datasets.
In conclusion, EVA-CLIP-18B is the most important and highest-performing open-source CLIP mannequin, boasting 18 billion parameters. Applying EVA’s weak-to-strong imaginative and prescient scaling precept achieves distinctive zero-shot top-1 accuracy throughout 27 picture classification benchmarks. This scaling strategy persistently improves efficiency with out reaching saturation, pushing the boundaries of imaginative and prescient mannequin capabilities. Notably, EVA-CLIP-18B reveals robustness in visible representations, sustaining efficiency throughout numerous ImageNet variants, together with adversarial ones. Its versatility and effectiveness are demonstrated throughout a number of datasets, spanning picture classification, image-text retrieval, and video classification duties, marking a major development in CLIP mannequin capabilities.
Check out the Paper. All credit score for this analysis goes to the researchers of this mission. Also, don’t overlook to observe us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our e-newsletter..
Don’t Forget to affix our Telegram Channel
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is obsessed with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.