

Baidu AI Research group has simply launched ERNIE-4.5-21B-A3B-Thinking, a brand new reasoning-focused giant language mannequin designed round effectivity, long-context reasoning, and power integration. Being a part of the ERNIE-4.5 household, this mannequin is a Mixture-of-Experts (MoE) structure with 21B whole parameters however solely 3B lively parameters per token, making it computationally environment friendly whereas sustaining aggressive reasoning functionality. Released below the Apache-2.0 license, it’s accessible for each analysis and business deployment through Hugging Face.
What is the architectural design of ERNIE-4.5-21B-A3B-Thinking?
ERNIE-4.5-21B-A3B-Thinking is constructed on a Mixture-of-Experts spine. Instead of activating all 21B parameters, the router selects a subset of consultants, leading to 3B lively parameters per token. This construction reduces computation with out compromising the specialization of various consultants. The analysis group applies router orthogonalization loss and token-balanced loss to encourage numerous skilled activation and secure coaching.
This design supplies a center floor between small dense fashions and ultra-large methods. The analysis group’s assumptions embody a idea that ~3B lively parameters per token could signify a sensible candy spot for reasoning efficiency versus deployment effectivity.
How does the mannequin deal with long-context reasoning?
A defining functionality of ERNIE-4.5-21B-A3B-Thinking is its 128K context size. This permits the mannequin to course of very lengthy paperwork, carry out prolonged multi-step reasoning, and combine structured information sources similar to educational papers or multi-file codebases.
The analysis group achieves this by progressive scaling of Rotary Position Embeddings (RoPE)—steadily rising the frequency base from 10K as much as 500K throughout coaching. Additional optimizations, together with FlashMask consideration and memory-efficient scheduling, make these long-context operations computationally possible.
What coaching technique helps its reasoning?
The mannequin follows the multi-stage recipe outlined throughout the ERNIE-4.5 household:
- Stage I – Text-only pretraining builds the core language spine, beginning with 8K context and increasing to 128K.
- Stage II – Vision coaching is skipped for this text-only variant.
- Stage III – Joint multimodal coaching just isn’t used right here, as A3B-Thinking is only textual.
Post-training focuses on reasoning duties. The analysis group employs Supervised Fine-Tuning (SFT) throughout arithmetic, logic, coding, and science, adopted by Progressive Reinforcement Learning (PRL). Reinforcement phases start with logic, then prolong to arithmetic and programming, and eventually to broader reasoning duties. This is enhanced by Unified Preference Optimization (UPO), which integrates choice studying with PPO to stabilize alignment and scale back reward hacking.
What function does device utilization play on this mannequin?
ERNIE-4.5-21B-A3B-Thinking helps structured device and performance calling, making it helpful for situations the place exterior computation or retrieval is required. Developers can combine it with vLLM, Transformers 4.54+, and FastDeploy. This tool-use functionality is especially suited for program synthesis, symbolic reasoning, and multi-agent workflows.
Built-in perform calling permits the mannequin to motive over lengthy contexts whereas dynamically invoking exterior APIs, a key requirement for utilized reasoning in enterprise methods.
How does ERNIE-4.5-21B-A3B-Thinking carry out on reasoning benchmarks?
It present sturdy efficiency enhancements throughout logical reasoning, arithmetic, scientific QA, and programming duties. In evaluations, the mannequin demonstrates:
- Enhanced accuracy in multi-step reasoning datasets, the place lengthy chains of thought are required.
- Competitiveness with bigger dense fashions on STEM reasoning duties.
- Stable textual content era and educational synthesis efficiency, benefiting from prolonged context coaching.
These outcomes recommend that the MoE construction amplifies reasoning specialization, making it environment friendly with out requiring trillion-scale dense parameters.
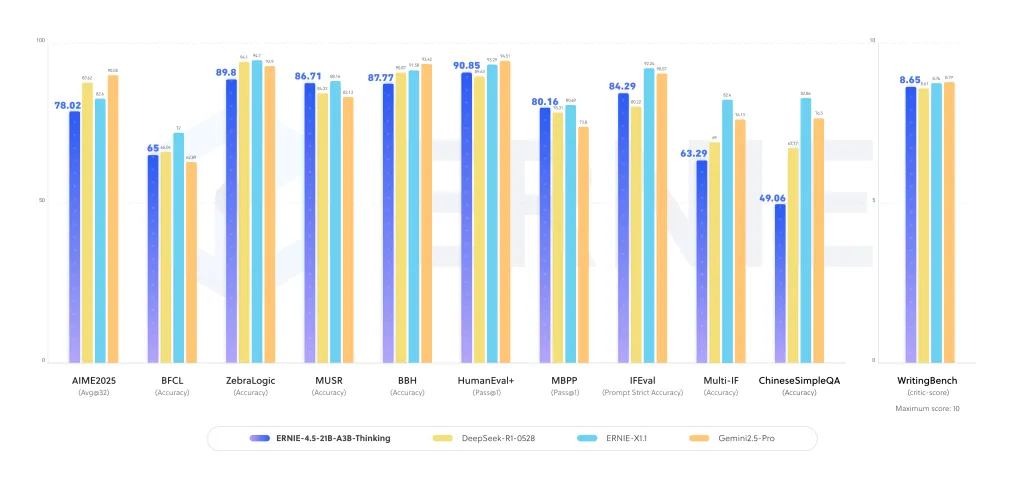
How does it evaluate to different reasoning-focused LLMs?
This launch will get into the panorama that features OpenAI’s o3, Anthropic’s Claude 4, DeepSearch-R1, and Qwen-3. Many of those opponents depend on dense architectures or bigger lively parameter counts. Baidu analysis group’s selection of a compact MoE with 3B lively parameters affords a special stability:
- Scalability: Sparse activation reduces compute overhead whereas scaling skilled capability.
- Long-context readiness: 128K context is straight skilled, not retrofitted.
- Commercial openness: Apache-2.0 license lowers adoption friction for enterprises.
Summary
ERNIE-4.5-21B-A3B-Thinking explains how deep reasoning might be achieved with out huge dense parameter counts. By combining environment friendly MoE routing, 128K context coaching, and power integration, Baidu’s analysis group affords a mannequin that balances research-grade reasoning with deployment feasibility.
Check out the Model on Hugging Face and PAPER. Feel free to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Also, be at liberty to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Artificial Intelligence for social good. His most up-to-date endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.