

Update — 2023/05/08: This publish has been up to date to incorporate open-source particulars for the Visual Blocks framework.
Recent deep learning advances have enabled a plethora of high-performance, real-time multimedia functions primarily based on machine learning (ML), equivalent to human physique segmentation for video and teleconferencing, depth estimation for 3D reconstruction, hand and physique monitoring for interplay, and audio processing for distant communication.
However, creating and iterating on these ML-based multimedia prototypes will be difficult and dear. It often entails a cross-functional group of ML practitioners who fine-tune the fashions, consider robustness, characterize strengths and weaknesses, examine efficiency within the end-use context, and develop the functions. Moreover, fashions are regularly up to date and require repeated integration efforts earlier than analysis can happen, which makes the workflow ill-suited to design and experiment.
In “Rapsai: Accelerating Machine Learning Prototyping of Multimedia Applications through Visual Programming”, introduced at CHI 2023, we describe a visible programming platform for fast and iterative growth of end-to-end ML-based multimedia functions. Visual Blocks for ML, previously known as Rapsai, supplies a no-code graph constructing expertise via its node-graph editor. Users can create and join totally different parts (nodes) to quickly construct an ML pipeline, and see the ends in real-time with out writing any code. We display how this platform allows a greater mannequin analysis expertise via interactive characterization and visualization of ML mannequin efficiency and interactive knowledge augmentation and comparability. We have launched the Visual Blocks for ML framework, alongside with a demo and Colab examples. Try it out your self right now.
 |
| Visual Blocks makes use of a node-graph editor that facilitates fast prototyping of ML-based multimedia functions. |
Formative research: Design targets for fast ML prototyping
To higher perceive the challenges of current fast prototyping ML options (LIME, VAC-CNN, EnsembleMatrix), we carried out a formative research (i.e., the method of gathering suggestions from potential customers early within the design means of a know-how product or system) utilizing a conceptual mock-up interface. Study members included seven laptop imaginative and prescient researchers, audio ML researchers, and engineers throughout three ML groups.
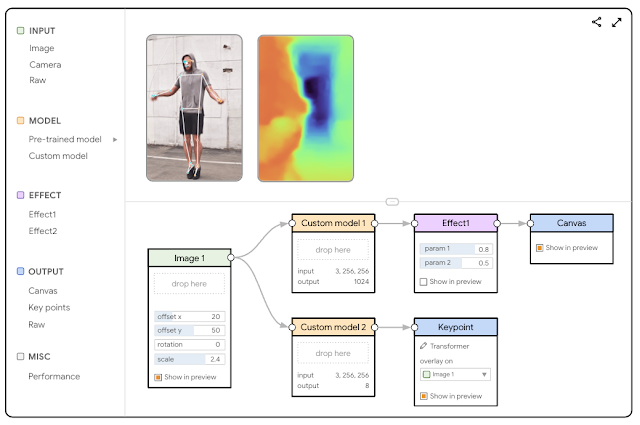 |
| The formative research used a conceptual mock-up interface to assemble early insights. |
Through this formative research, we recognized six challenges generally present in current prototyping options:
- The enter used to guage fashions sometimes differs from in-the-wild enter with precise customers when it comes to decision, side ratio, or sampling charge.
- Participants couldn’t shortly and interactively alter the enter knowledge or tune the mannequin.
- Researchers optimize the mannequin with quantitative metrics on a hard and fast set of knowledge, however real-world efficiency requires human reviewers to guage within the software context.
- It is troublesome to check variations of the mannequin, and cumbersome to share one of the best model with different group members to attempt it.
- Once the mannequin is chosen, it may be time-consuming for a group to make a bespoke prototype that showcases the mannequin.
- Ultimately, the mannequin is simply half of a bigger real-time pipeline, during which members need to look at intermediate outcomes to know the bottleneck.
These recognized challenges knowledgeable the event of the Visual Blocks system, which included six design targets: (1) develop a visible programming platform for quickly constructing ML prototypes, (2) help real-time multimedia person enter in-the-wild, (3) present interactive knowledge augmentation, (4) evaluate mannequin outputs with side-by-side outcomes, (5) share visualizations with minimal effort, and (6) present off-the-shelf fashions and datasets.
Node-graph editor for visually programming ML pipelines
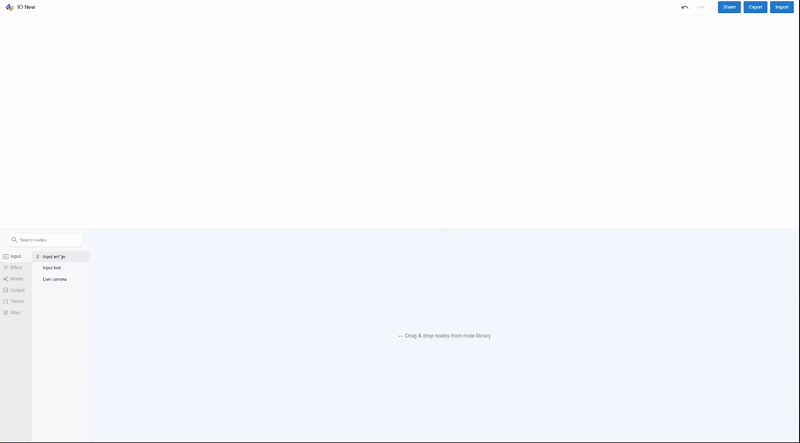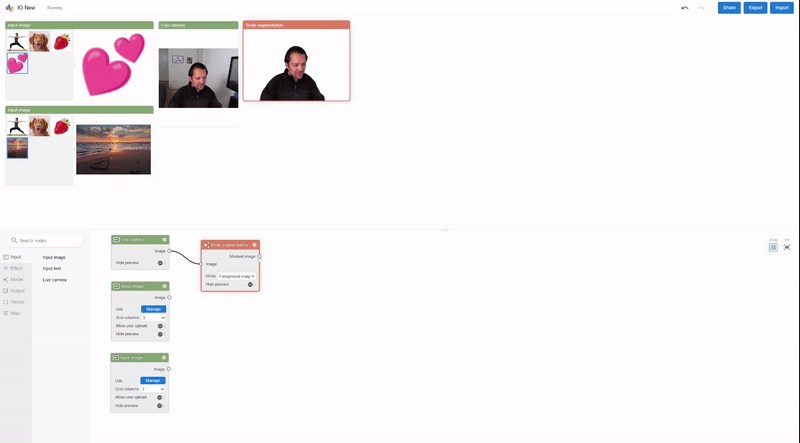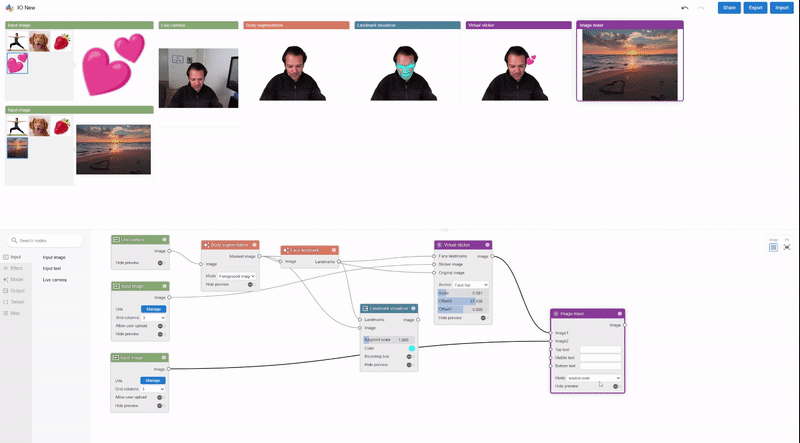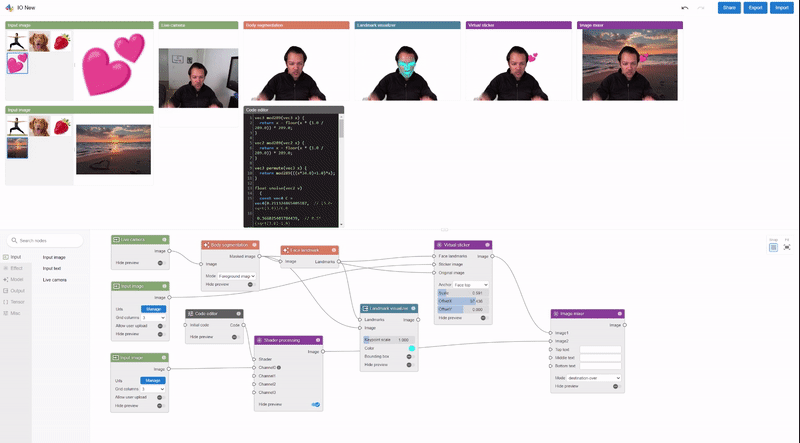
Visual Blocks is principally written in JavaScript and leverages TensorFlow.js and TensorFlow Lite for ML capabilities and three.js for graphics rendering. The interface allows customers to quickly construct and work together with ML fashions utilizing three coordinated views: (1) a Nodes Library that incorporates over 30 nodes (e.g., Image Processing, Body Segmentation, Image Comparison) and a search bar for filtering, (2) a Node-graph Editor that permits customers to construct and modify a multimedia pipeline by dragging and including nodes from the Nodes Library, and (3) a Preview Panel that visualizes the pipeline’s enter and output, alters the enter and intermediate outcomes, and visually compares totally different fashions.
 |
| The visible programming interface permits customers to shortly develop and consider ML fashions by composing and previewing node-graphs with real-time outcomes. |
Iterative design, growth, and analysis of distinctive fast prototyping capabilities
Over the final 12 months, we’ve been iteratively designing and enhancing the Visual Blocks platform. Weekly suggestions periods with the three ML groups from the formative research confirmed appreciation for the platform’s distinctive capabilities and its potential to speed up ML prototyping via:
- Support for varied forms of enter knowledge (picture, video, audio) and output modalities (graphics, sound).
- A library of pre-trained ML fashions for frequent duties (physique segmentation, landmark detection, portrait depth estimation) and customized mannequin import choices.
- Interactive knowledge augmentation and manipulation with drag-and-drop operations and parameter sliders.
- Side-by-side comparability of a number of fashions and inspection of their outputs at totally different phases of the pipeline.
- Quick publishing and sharing of multimedia pipelines on to the net.
Evaluation: Four case research
To consider the usability and effectiveness of Visual Blocks, we carried out 4 case research with 15 ML practitioners. They used the platform to prototype totally different multimedia functions: portrait depth with relighting results, scene depth with visible results, alpha matting for digital conferences, and audio denoising for communication.
 |
| The system streamlining comparability of two Portrait Depth fashions, together with custom-made visualization and results. |
With a brief introduction and video tutorial, members have been in a position to shortly determine variations between the fashions and choose a greater mannequin for his or her use case. We discovered that Visual Blocks helped facilitate fast and deeper understanding of mannequin advantages and trade-offs:
“It gives me intuition about which data augmentation operations that my model is more sensitive [to], then I can go back to my training pipeline, maybe increase the amount of data augmentation for those specific steps that are making my model more sensitive.” (Participant 13)
“It’s a fair amount of work to add some background noise, I have a script, but then every time I have to find that script and modify it. I’ve always done this in a one-off way. It’s simple but also very time consuming. This is very convenient.” (Participant 15)
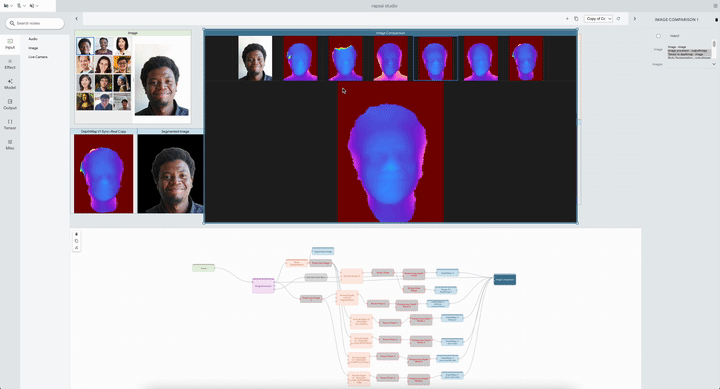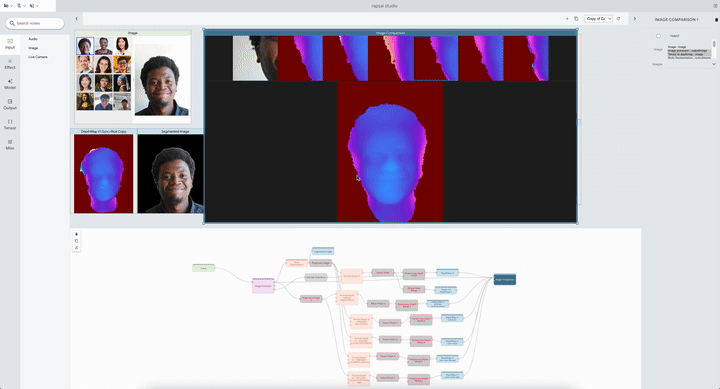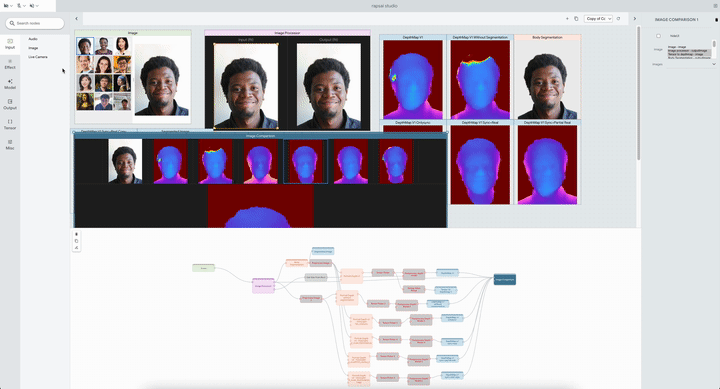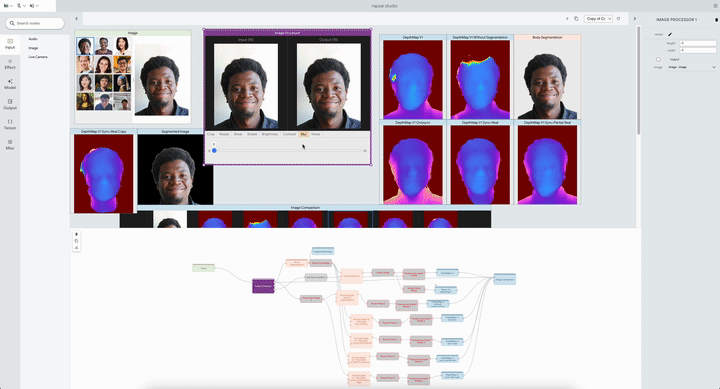 |
| The system permits researchers to check a number of Portrait Depth fashions at totally different noise ranges, serving to ML practitioners determine the strengths and weaknesses of every. |
In a post-hoc survey utilizing a seven-point Likert scale, members reported Visual Blocks to be extra clear about the way it arrives at its last outcomes than Colab (Visual Blocks 6.13 ± 0.88 vs. Colab 5.0 ± 0.88, < .005) and extra collaborative with customers to return up with the outputs (Visual Blocks 5.73 ± 1.23 vs. Colab 4.15 ± 1.43, < .005). Although Colab assisted customers in pondering via the duty and controlling the pipeline extra successfully via programming, Users reported that they have been in a position to full duties in Visual Blocks in only a few minutes that would usually take as much as an hour or extra. For instance, after watching a 4-minute tutorial video, all members have been in a position to construct a customized pipeline in Visual Blocks from scratch inside quarter-hour (10.72 ± 2.14). Participants often spent lower than 5 minutes (3.98 ± 1.95) getting the preliminary outcomes, then have been attempting out totally different enter and output for the pipeline.
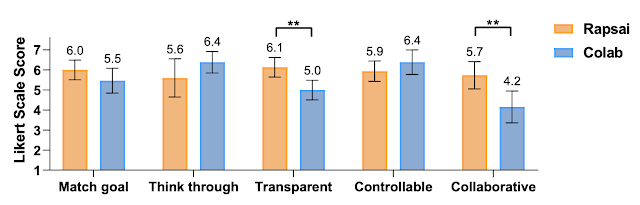 |
| User scores between Rapsai (preliminary prototype of Visual Blocks) and Colab throughout 5 dimensions. |
More ends in our paper confirmed that Visual Blocks helped members speed up their workflow, make extra knowledgeable selections about mannequin choice and tuning, analyze strengths and weaknesses of various fashions, and holistically consider mannequin habits with real-world enter.
Conclusions and future instructions
Visual Blocks lowers growth limitations for ML-based multimedia functions. It empowers customers to experiment with out worrying about coding or technical particulars. It additionally facilitates collaboration between designers and builders by offering a standard language for describing ML pipelines. In the longer term, we plan to open this framework up for the neighborhood to contribute their very own nodes and combine it into many alternative platforms. We anticipate visible programming for machine learning to be a standard interface throughout ML tooling going ahead.
Acknowledgements
This work is a collaboration throughout a number of groups at Google. Key contributors to the venture embrace Ruofei Du, Na Li, Jing Jin, Michelle Carney, Xiuxiu Yuan, Kristen Wright, Mark Sherwood, Jason Mayes, Lin Chen, Jun Jiang, Scott Miles, Maria Kleiner, Yinda Zhang, Anuva Kulkarni, Xingyu “Bruce” Liu, Ahmed Sabie, Sergio Escolano, Abhishek Kar, Ping Yu, Ram Iyengar, Adarsh Kowdle, and Alex Olwal.
We want to prolong our due to Jun Zhang, Satya Amarapalli and Sarah Heimlich for a couple of early-stage prototypes, Sean Fanello, Danhang Tang, Stephanie Debats, Walter Korman, Anne Menini, Joe Moran, Eric Turner, and Shahram Izadi for offering preliminary suggestions for the manuscript and the weblog publish. We would additionally wish to thank our CHI 2023 reviewers for his or her insightful suggestions.