

The previous few years have seen speedy progress in techniques that may mechanically course of advanced enterprise paperwork and switch them into structured objects. A system that may mechanically extract knowledge from paperwork, e.g., receipts, insurance coverage quotes, and monetary statements, has the potential to dramatically enhance the effectivity of enterprise workflows by avoiding error-prone, guide work. Recent fashions, primarily based on the Transformer structure, have proven spectacular positive factors in accuracy. Larger fashions, resembling PaLM 2, are additionally being leveraged to additional streamline these enterprise workflows. However, the datasets used in tutorial literature fail to seize the challenges seen in real-world use instances. Consequently, tutorial benchmarks report robust mannequin accuracy, however these similar fashions do poorly when used for advanced real-world functions.
In “VRDU: A Benchmark for Visually-rich Document Understanding”, offered at KDD 2023, we announce the discharge of the brand new Visually Rich Document Understanding (VRDU) dataset that goals to bridge this hole and assist researchers higher monitor progress on document understanding duties. We checklist 5 necessities for document understanding benchmark, primarily based on the sorts of real-world paperwork for which document understanding fashions are incessantly used. Then, we describe how most datasets at the moment utilized by the analysis group fail to fulfill a number of of those necessities, whereas VRDU meets all of them. We are excited to announce the general public launch of the VRDU dataset and analysis code beneath a Creative Commons license.
Benchmark necessities
First, we in contrast state-of-the-art mannequin accuracy (e.g., with FormNet and LayoutLMv2) on real-world use instances to tutorial benchmarks (e.g., FUNSD, CORD, SROIE). We noticed that state-of-the-art fashions didn’t match tutorial benchmark outcomes and delivered a lot decrease accuracy in the true world. Next, we in contrast typical datasets for which document understanding fashions are incessantly used with tutorial benchmarks and recognized 5 dataset necessities that permit a dataset to higher seize the complexity of real-world functions:
- Rich Schema: In observe, we see all kinds of wealthy schemas for structured extraction. Entities have totally different knowledge varieties (numeric, strings, dates, and so forth.) that could be required, non-obligatory, or repeated in a single document or might even be nested. Extraction duties over easy flat schemas like (header, query, reply) don’t replicate typical issues encountered in observe.
- Layout-Rich Documents: The paperwork ought to have advanced format components. Challenges in sensible settings come from the truth that paperwork might include tables, key-value pairs, swap between single-column and double-column format, have various font-sizes for various sections, embody photos with captions and even footnotes. Contrast this with datasets the place most paperwork are organized in sentences, paragraphs, and chapters with part headers — the sorts of paperwork which can be sometimes the main focus of basic pure language processing literature on lengthy inputs.
- Diverse Templates: A benchmark ought to embody totally different structural layouts or templates. It is trivial for a high-capacity mannequin to extract from a specific template by memorizing the construction. However, in observe, one wants to have the ability to generalize to new templates/layouts, a capability that the train-test break up in a benchmark ought to measure.
- High-Quality OCR: Documents ought to have high-quality Optical Character Recognition (OCR) outcomes. Our goal with this benchmark is to concentrate on the VRDU job itself and to exclude the variability introduced on by the selection of OCR engine.
- Token-Level Annotation: Documents ought to include ground-truth annotations that may be mapped again to corresponding enter textual content, so that every token might be annotated as a part of the corresponding entity. This is in distinction with merely offering the textual content of the worth to be extracted for the entity. This is vital to producing clear coaching knowledge the place we should not have to fret about incidental matches to the given worth. For occasion, in some receipts, the ‘total-before-tax’ discipline might have the identical worth because the ‘total’ discipline if the tax quantity is zero. Having token stage annotations prevents us from producing coaching knowledge the place each situations of the matching worth are marked as ground-truth for the ‘total’ discipline, thus producing noisy examples.
 |
VRDU datasets and duties
The VRDU dataset is a mixture of two publicly accessible datasets, Registration Forms and Ad-Buy varieties. These datasets present examples which can be consultant of real-world use instances, and fulfill the 5 benchmark necessities described above.
The Ad-buy Forms dataset consists of 641 paperwork with political commercial particulars. Each document is both an bill or receipt signed by a TV station and a marketing campaign group. The paperwork use tables, multi-columns, and key-value pairs to document the commercial data, such because the product identify, broadcast dates, complete worth, and launch date and time.
The Registration Forms dataset consists of 1,915 paperwork with details about international brokers registering with the US authorities. Each document data important details about international brokers concerned in actions that require public disclosure. Contents embody the identify of the registrant, the handle of associated bureaus, the aim of actions, and different particulars.
We gathered a random pattern of paperwork from the general public Federal Communications Commission (FCC) and Foreign Agents Registration Act (FARA) websites, and transformed the photographs to textual content utilizing Google Cloud’s OCR. We discarded a small variety of paperwork that have been a number of pages lengthy and the processing didn’t full in beneath two minutes. This additionally allowed us to keep away from sending very lengthy paperwork for guide annotation — a job that may take over an hour for a single document. Then, we outlined the schema and corresponding labeling directions for a staff of annotators skilled with document-labeling duties.
The annotators have been additionally supplied with a number of pattern labeled paperwork that we labeled ourselves. The job required annotators to look at every document, draw a bounding field round each incidence of an entity from the schema for every document, and affiliate that bounding field with the goal entity. After the primary spherical of labeling, a pool of consultants have been assigned to evaluation the outcomes. The corrected outcomes are included in the revealed VRDU dataset. Please see the paper for extra particulars on the labeling protocol and the schema for every dataset.
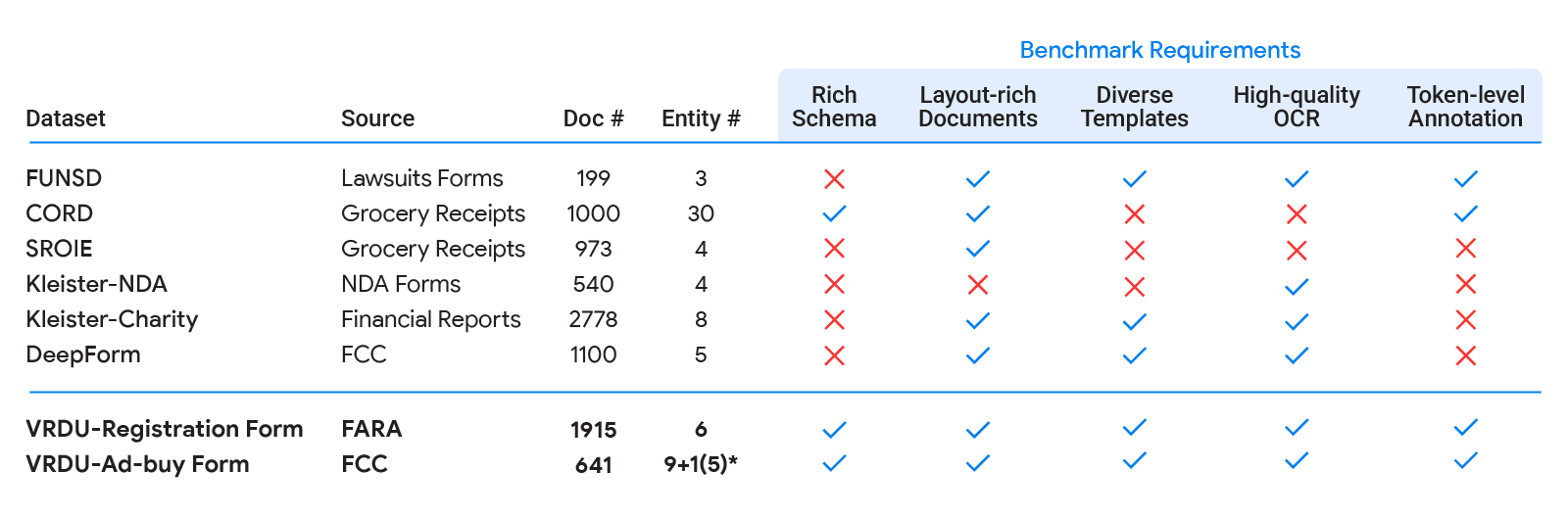 |
| Existing tutorial benchmarks (FUNSD, CORD, SROIE, Kleister-NDA, Kleister-Charity, DeepForm) fall-short on a number of of the 5 necessities we recognized for document understanding benchmark. VRDU satisfies all of them. See our paper for background on every of those datasets and a dialogue on how they fail to fulfill a number of of the necessities. |
We constructed 4 totally different mannequin coaching units with 10, 50, 100, and 200 samples respectively. Then, we evaluated the VRDU datasets utilizing three duties (described under): (1) Single Template Learning, (2) Mixed Template Learning, and (3) Unseen Template Learning. For every of those duties, we included 300 paperwork in the testing set. We consider fashions utilizing the F1 rating on the testing set.
- Single Template Learning (STL): This is the best situation the place the coaching, testing, and validation units solely include a single template. This easy job is designed to judge a mannequin’s capacity to cope with a set template. Naturally, we anticipate very excessive F1 scores (0.90+) for this job.
- Mixed Template Learning (MTL): This job is much like the duty that the majority associated papers use: the coaching, testing, and validation units all include paperwork belonging to the identical set of templates. We randomly pattern paperwork from the datasets and assemble the splits to verify the distribution of every template shouldn’t be modified throughout sampling.
- Unseen Template Learning (UTL): This is probably the most difficult setting, the place we consider if the mannequin can generalize to unseen templates. For instance, in the Registration Forms dataset, we practice the mannequin with two of the three templates and take a look at the mannequin with the remaining one. The paperwork in the coaching, testing, and validation units are drawn from disjoint units of templates. To our information, earlier benchmarks and datasets don’t explicitly present such a job designed to judge the mannequin’s capacity to generalize to templates not seen throughout coaching.
The goal is to have the ability to consider fashions on their knowledge effectivity. In our paper, we in contrast two current fashions utilizing the STL, MTL, and UTL duties and made three observations. First, not like with different benchmarks, VRDU is difficult and reveals that fashions have loads of room for enhancements. Second, we present that few-shot efficiency for even state-of-the-art fashions is surprisingly low with even the most effective fashions ensuing in lower than an F1 rating of 0.60. Third, we present that fashions wrestle to cope with structured repeated fields and carry out significantly poorly on them.
Conclusion
We launch the brand new Visually Rich Document Understanding (VRDU) dataset that helps researchers higher monitor progress on document understanding duties. We describe why VRDU higher displays sensible challenges in this area. We additionally current experiments displaying that VRDU duties are difficult, and up to date fashions have substantial headroom for enhancements in comparison with the datasets sometimes used in the literature with F1 scores of 0.90+ being typical. We hope the discharge of the VRDU dataset and analysis code helps analysis groups advance the state-of-the-art in document understanding.
Acknowledgements
Many because of Zilong Wang, Yichao Zhou, Wei Wei, and Chen-Yu Lee, who co-authored the paper together with Sandeep Tata. Thanks to Marc Najork, Riham Mansour and quite a few companions throughout Google Research and the Cloud AI staff for offering helpful insights. Thanks to John Guilyard for creating the animations in this submit.