

Google Ads infrastructure runs on an inside information warehouse referred to as Napa. Billions of reporting queries, which energy vital dashboards utilized by promoting purchasers to measure marketing campaign efficiency, run on tables saved in Napa. These tables include data of advertisements efficiency which can be keyed utilizing specific prospects and the marketing campaign identifiers with which they’re related. Keys are tokens which can be used each to affiliate an advertisements document with a selected consumer and marketing campaign (e.g., customer_id, campaign_id) and for environment friendly retrieval. A document comprises dozens of keys, so purchasers use reporting queries to specify keys wanted to filter the information to grasp advertisements efficiency (e.g., by area, machine and metrics resembling clicks, and so forth.). What makes this downside difficult is that the information is skewed since queries require various ranges of effort to be answered and have stringent latency expectations. Specifically, some queries require the use of thousands and thousands of data whereas others are answered with only a few.
To this finish, in “Progressive Partitioning for Parallelized Query Execution in Napa”, introduced at VLDB 2023, we describe how the Napa information warehouse determines the quantity of machine sources wanted to reply reporting queries whereas assembly strict latency targets. We introduce a brand new progressive question partitioning algorithm that may parallelize question execution within the presence of complicated information skews to carry out persistently nicely in a matter of just a few milliseconds. Finally, we exhibit how Napa permits Google Ads infrastructure to serve billions of queries each day.
Query processing challenges
When a consumer inputs a reporting question, the principle problem is to find out easy methods to parallelize the question successfully. Napa’s parallelization approach breaks up the question into even sections which can be equally distributed throughout accessible machines, which then course of these in parallel to considerably scale back question latency. This is completed by estimating the quantity of data related with a specified key, and assigning kind of equal quantities of work to machines. However, this estimation isn’t good since reviewing all data would require the identical effort as answering the question. A machine that processes considerably greater than others would lead to run-time skews and poor efficiency. Each machine additionally must have adequate work since unnecessary parallelism results in underutilized infrastructure. Finally, parallelization needs to be a per question choice that have to be executed near-perfectly billions of instances, or the question could miss the stringent latency necessities.
The reporting question instance beneath extracts the data denoted by keys (i.e., customer_id and campaign_id) after which computes an combination (i.e., SUM(price)) from an advertiser desk. In this instance the quantity of data is simply too massive to course of on a single machine, so Napa wants to make use of a subsequent key (e.g., adgroup_id) to additional break up the gathering of data in order that equal distribution of work is achieved. It is vital to notice that at petabyte scale, the scale of the information statistics wanted for parallelization could also be a number of terabytes. This implies that the issue is not only about accumulating huge quantities of metadata, but additionally how it’s managed.
SELECT customer_id, campaign_id, SUM(price)
FROM advertiser_table
WHERE customer_id in (1, 7, ..., x )
AND campaign_id in (10, 20, ..., y)
GROUP BY customer_id, campaign_id;
This reporting question instance extracts data denoted by keys (i.e., customer_id and campaign_id) after which computes an combination (i.e., SUM(price)) from an advertiser desk. The question effort is set by the keys’ included within the question. Keys belonging to purchasers with bigger campaigns could contact thousands and thousands of data for the reason that information quantity instantly correlates with the scale of the advertisements marketing campaign. This disparity of matching data based mostly on keys displays the skewness in information, which makes question processing a difficult downside. |
An efficient answer minimizes the quantity of metadata wanted, focuses effort totally on the skewed half of the important thing area to partition information effectively, and works nicely inside the allotted time. For instance, if the question latency is just a few hundred milliseconds, partitioning ought to take now not than tens of milliseconds. Finally, a parallelization course of ought to decide when it is reached the absolute best partitioning that considers question latency expectations. To this finish, we’ve developed a progressive partitioning algorithm that we describe later on this article.
Managing the information deluge
Tables in Napa are always up to date, so we use log-structured merge forests (LSM tree) to prepare the deluge of desk updates. LSM is a forest of sorted information that’s temporally organized with a B-tree index to help environment friendly key lookup queries. B-trees retailer abstract info of the sub-trees in a hierarchical method. Each B-tree node data the quantity of entries current in each subtree, which aids within the parallelization of queries. LSM permits us to decouple the method of updating the tables from the mechanics of question serving within the sense that reside queries go towards a unique model of the information, which is atomically up to date as soon as the following batch of ingest (referred to as delta) has been totally ready for querying.
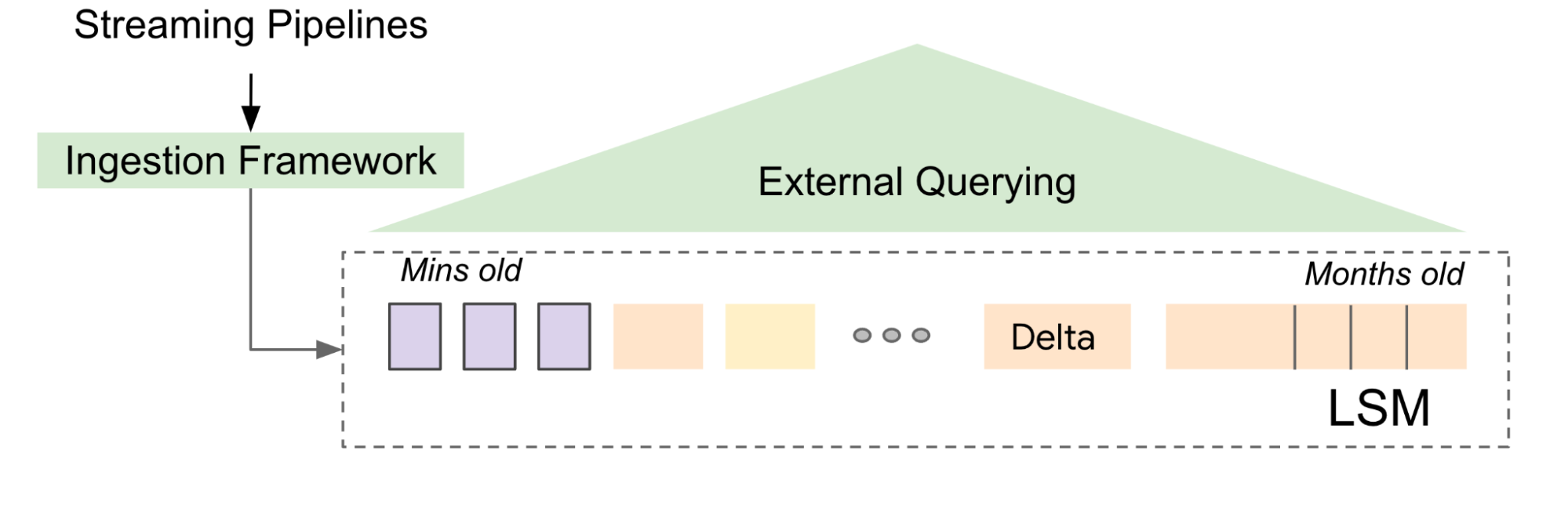 |
The partitioning downside
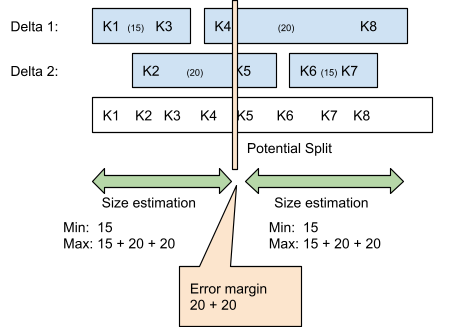
The information partitioning downside in our context is that we’ve a massively massive desk that’s represented as an LSM tree. In the determine beneath, Delta 1 and a couple of each have their very own B-tree, and collectively signify 70 data. Napa breaks the data into two items, and assigns each piece to a unique machine. The downside turns into a partitioning downside of a forest of timber and requires a tree-traversal algorithm that may shortly break up the timber into two equal components.
To keep away from visiting all of the nodes of the tree, we introduce the idea of “good enough” partitioning. As we start slicing and partitioning the tree into two components, we keep an estimate of how unhealthy our present reply can be if we terminated the partitioning course of at that on the spot. This is the yardstick of how shut we’re to the reply and is represented beneath by a complete error margin of 40 (at this level of execution, the 2 items are anticipated to be between 15 and 35 data in measurement, the uncertainty provides as much as 40). Each subsequent traversal step reduces the error estimate, and if the 2 items are roughly equal, it stops the partitioning course of. This course of continues till the specified error margin is reached, at which era we’re assured that the 2 items are kind of equal.
 |
Progressive partitioning algorithm
Progressive partitioning encapsulates the notion of “good enough” in that it makes a sequence of strikes to scale back the error estimate. The enter is a set of B-trees and the purpose is to chop the timber into items of kind of equal measurement. The algorithm traverses one of the timber (“drill down” within the determine) which leads to a discount of the error estimate. The algorithm is guided by statistics which can be saved with each node of the tree in order that it makes an knowledgeable set of strikes at each step. The problem right here is to resolve easy methods to direct effort in the absolute best manner in order that the error certain reduces shortly within the fewest attainable steps. Progressive partitioning is conducive for our use-case for the reason that longer the algorithm runs, the extra equal the items change into. It additionally implies that if the algorithm is stopped at any level, one nonetheless will get good partitioning, the place the standard corresponds to the time spent.
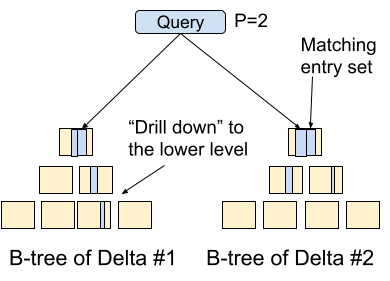 |
Prior work on this area makes use of a sampled desk to drive the partitioning course of, whereas the Napa method makes use of a B-tree. As talked about earlier, even only a pattern from a petabyte desk may be large. A tree-based partitioning technique can obtain partitioning far more effectively than a sample-based method, which doesn’t use a tree group of the sampled data. We examine progressive partitioning with an alternate method, the place sampling of the desk at varied resolutions (e.g., 1 document pattern each 250 MB and so forth) aids the partitioning of the question. Experimental outcomes present the relative speedup from progressive partitioning for queries requiring various numbers of machines. These outcomes exhibit that progressive partitioning is way quicker than present approaches and the speedup will increase as the scale of the question will increase.
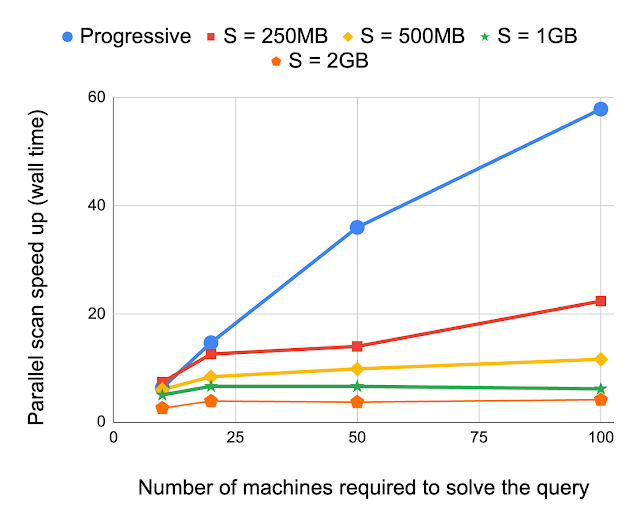 |
Conclusion
Napa’s progressive partitioning algorithm effectively optimizes database queries, enabling Google Ads to serve consumer reporting queries billions of instances each day. We notice that tree traversal is a typical approach that college students in introductory laptop science programs use, but it additionally serves a vital use-case at Google. We hope that this text will encourage our readers, because it demonstrates how easy methods and punctiliously designed information buildings may be remarkably potent if used nicely. Check out the paper and a latest discuss describing Napa to study extra.
Acknowledgements
This weblog publish describes a collaborative effort between Junichi Tatemura, Tao Zou, Jagan Sankaranarayanan, Yanlai Huang, Jim Chen, Yupu Zhang, Kevin Lai, Hao Zhang, Gokul Nath Babu Manoharan, Goetz Graefe, Divyakant Agrawal, Brad Adelberg, Shilpa Kolhar and Indrajit Roy.