

Creating robots that exhibit strong and dynamic locomotion capabilities, just like animals or people, has been a long-standing purpose within the robotics group. In addition to finishing duties rapidly and effectively, agility permits legged robots to maneuver by advanced environments which are in any other case troublesome to traverse. Researchers at Google have been pursuing agility for a number of years and throughout numerous type elements. Yet, whereas researchers have enabled robots to hike or bounce over some obstacles, there’s nonetheless no typically accepted benchmark that comprehensively measures robotic agility or mobility. In distinction, benchmarks are driving forces behind the event of machine studying, similar to ImageNet for laptop imaginative and prescient, and OpenAI Gym for reinforcement studying (RL).
In “Barkour: Benchmarking Animal-level Agility with Quadruped Robots”, we introduce the Barkour agility benchmark for quadruped robots, alongside with a Transformer-based generalist locomotion coverage. Inspired by canine agility competitions, a legged robotic should sequentially show a wide range of abilities, together with transferring in numerous instructions, traversing uneven terrains, and leaping over obstacles inside a restricted timeframe to efficiently full the benchmark. By offering a various and difficult impediment course, the Barkour benchmark encourages researchers to develop locomotion controllers that transfer quick in a controllable and versatile method. Furthermore, by tying the efficiency metric to actual canine efficiency, we offer an intuitive metric to know the robotic efficiency with respect to their animal counterparts.
| We invited a handful of dooglers to strive the impediment course to make sure that our agility aims had been practical and difficult. Small canines full the impediment course in roughly 10s, whereas our robotic’s typical efficiency hovers round 20s. |
Barkour benchmark
The Barkour scoring system makes use of a per impediment and an general course goal time primarily based on the goal pace of small canines within the novice agility competitions (about 1.7m/s). Barkour scores vary from 0 to 1, with 1 equivalent to the robotic efficiently traversing all of the obstacles alongside the course inside the allotted time of roughly 10 seconds, the common time wanted for a similar-sized canine to traverse the course. The robotic receives penalties for skipping, failing obstacles, or transferring too slowly.
Our commonplace course consists of 4 distinctive obstacles in a 5m x 5m space. This is a denser and smaller setup than a typical canine competitors to permit for simple deployment in a robotics lab. Beginning at first desk, the robotic must weave by a set of poles, climb an A-frame, clear a 0.5m broad bounce after which step onto the top desk. We selected this subset of obstacles as a result of they take a look at a various set of abilities whereas preserving the setup inside a small footprint. As is the case for actual canine agility competitions, the Barkour benchmark could be simply tailored to a bigger course space and will incorporate a variable variety of obstacles and course configurations.
 |
| Overview of the Barkour benchmark’s impediment course setup, which consists of weave poles, an A-frame, a broad bounce, and pause tables. The intuitive scoring mechanism, impressed by canine agility competitions, balances pace, agility and efficiency and could be simply modified to include different sorts of obstacles or course configurations. |
Learning agile locomotion abilities
The Barkour benchmark incorporates a various set of obstacles and a delayed reward system, which pose a major problem when coaching a single coverage that may full all the impediment course. So with a purpose to set a robust efficiency baseline and exhibit the effectiveness of the benchmark for robotic agility analysis, we undertake a student-teacher framework mixed with a zero-shot sim-to-real strategy. First, we practice particular person specialist locomotion abilities (trainer) for various obstacles utilizing on-policy RL strategies. In specific, we leverage latest advances in large-scale parallel simulation to equip the robotic with particular person abilities, together with strolling, slope climbing, and leaping insurance policies.
Next, we practice a single coverage (scholar) that performs all the talents and transitions in between through the use of a student-teacher framework, primarily based on the specialist abilities we beforehand skilled. We use simulation rollouts to create datasets of state-action pairs for every one of many specialist abilities. This dataset is then distilled right into a single Transformer-based generalist locomotion coverage, which may deal with numerous terrains and modify the robotic’s gait primarily based on the perceived surroundings and the robotic’s state.
 |
During deployment, we pair the locomotion transformer coverage that’s able to performing a number of abilities with a navigation controller that gives velocity instructions primarily based on the robotic’s place. Our skilled coverage controls the robotic primarily based on the robotic’s environment represented as an elevation map, velocity instructions, and on-board sensory info offered by the robotic.
| Deployment pipeline for the locomotion transformer structure. At deployment time, a high-level navigation controller guides the actual robotic by the impediment course by sending instructions to the locomotion transformer coverage. |
Robustness and repeatability are troublesome to attain once we purpose for peak efficiency and most pace. Sometimes, the robotic would possibly fail when overcoming an impediment in an agile method. To deal with failures we practice a restoration coverage that rapidly will get the robotic again on its toes, permitting it to proceed the episode.
Evaluation
We consider the Transformer-based generalist locomotion coverage utilizing custom-built quadruped robots and present that by optimizing for the proposed benchmark, we receive agile, strong, and versatile abilities for our robotic in the actual world. We additional present evaluation for numerous design selections in our system and their influence on the system efficiency.
 |
| Model of the custom-built robots used for analysis. |
We deploy each the specialist and generalist insurance policies to {hardware} (zero-shot sim-to-real). The robotic’s goal trajectory is offered by a set of waypoints alongside the assorted obstacles. In the case of the specialist insurance policies, we change between specialist insurance policies through the use of a hand-tuned coverage switching mechanism that selects probably the most appropriate coverage given the robotic’s place.
| Typical efficiency of our agile locomotion insurance policies on the Barkour benchmark. Our custom-built quadruped robotic robustly navigates the terrain’s obstacles by leveraging numerous abilities realized utilizing RL in simulation. |
We discover that fairly often our insurance policies can deal with sudden occasions and even {hardware} degradation leading to good common efficiency, however failures are nonetheless doable. As illustrated within the picture beneath, in case of failures, our restoration coverage rapidly will get the robotic again on its toes, permitting it to proceed the episode. By combining the restoration coverage with a easy walk-back-to-start coverage, we’re in a position to run repeated experiments with minimal human intervention to measure the robustness.
| Qualitative instance of robustness and restoration behaviors. The robotic journeys and rolls over after heading down the A-frame. This triggers the restoration coverage, which permits the robotic to get again up and proceed the course. |
We discover that throughout numerous evaluations, the one generalist locomotion transformer coverage and the specialist insurance policies with the coverage switching mechanism obtain comparable efficiency. The locomotion transformer coverage has a barely decrease common Barkour rating, however reveals smoother transitions between behaviors and gaits.
| Measuring robustness of the totally different insurance policies throughout numerous runs on the Barkour benchmark. |
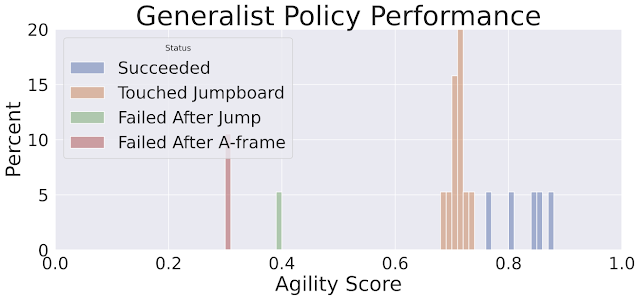 |
| Histogram of the agility scores for the locomotion transformer coverage. The highest scores proven in blue (0.75 – 0.9) signify the runs the place the robotic efficiently completes all obstacles. |
Conclusion
We imagine that creating a benchmark for legged robotics is a crucial first step in quantifying progress towards animal-level agility. To set up a robust baseline, we investigated a zero-shot sim-to-real strategy, making the most of large-scale parallel simulation and up to date developments in coaching Transformer-based architectures. Our findings exhibit that Barkour is a difficult benchmark that may be simply personalized, and that our learning-based technique for fixing the benchmark supplies a quadruped robotic with a single low-level coverage that may carry out a wide range of agile low-level abilities.
Acknowledgments
The authors of this submit are actually a part of Google DeepMind. We want to thank our co-authors at Google DeepMind and our collaborators at Google Research: Wenhao Yu, J. Chase Kew, Tingnan Zhang, Daniel Freeman, Kuang-Hei Lee, Lisa Lee, Stefano Saliceti, Vincent Zhuang, Nathan Batchelor, Steven Bohez, Federico Casarini, Jose Enrique Chen, Omar Cortes, Erwin Coumans, Adil Dostmohamed, Gabriel Dulac-Arnold, Alejandro Escontrela, Erik Frey, Roland Hafner, Deepali Jain, Yuheng Kuang, Edward Lee, Linda Luu, Ofir Nachum, Ken Oslund, Jason Powell, Diego Reyes, Francesco Romano, Feresteh Sadeghi, Ron Sloat, Baruch Tabanpour, Daniel Zheng, Michael Neunert, Raia Hadsell, Nicolas Heess, Francesco Nori, Jeff Seto, Carolina Parada, Vikas Sindhwani, Vincent Vanhoucke, and Jie Tan. We would additionally prefer to thank Marissa Giustina, Ben Jyenis, Gus Kouretas, Nubby Lee, James Lubin, Sherry Moore, Thinh Nguyen, Krista Reymann, Satoshi Kataoka, Trish Blazina, and the members of the robotics staff at Google DeepMind for his or her contributions to the venture.