
 Method to Enhance the Generalizability of Learning LLMs for Reasoning with Math Problem Solving as an Example")
One efficient technique to enhance the reasoning abilities of LLMs is to make use of supervised fine-tuning (SFT) with chain-of-thought (CoT) annotations. However, this strategy has limitations in phrases of generalization as a result of it closely is determined by the supplied CoT knowledge. In eventualities like math problem-solving, every query in the coaching knowledge usually has just one annotated reasoning path. In the preferrred case, it might be extra helpful for the algorithm to be taught from a number of annotated reasoning paths related with a given query, as this might improve its total efficiency and adaptableness.
Researchers from ByteDance Research lab counsel a sensible technique recognized as Reinforced Fine-Tuning (ReFT) to enhance the generalization capabilities of studying LLMs for reasoning, utilizing math problem-solving as an illustrative instance. The ReFT strategy begins by initially warming the mannequin by way of SFT. Subsequently, it leverages on-line reinforcement studying, particularly using the Proximal Policy Optimization (PPO) algorithm. During this fine-tuning course of, the mannequin is uncovered to numerous reasoning paths routinely sampled primarily based on the given query. The rewards for reinforcement studying come naturally from the ground-truth solutions, contributing to a extra strong and adaptable LLM for enhanced reasoning talents.
Recent analysis efforts have targeted on enhancing CoT immediate design and knowledge engineering, aiming to make CoT complete and fine-grained for step-by-step reasoning options. Some approaches have used Python packages as CoT prompts, demonstrating extra correct reasoning steps and vital enhancements over pure language CoT. Another line of work focuses on enhancing the high quality and amount of CoT knowledge, together with efforts to improve the quantity of CoT knowledge from OpenAI’s ChatGPT. Reinforcement studying has been utilized to fine-tuning paradigms to enhance efficiency over typical supervised fine-tuning, particularly for fixing math issues.
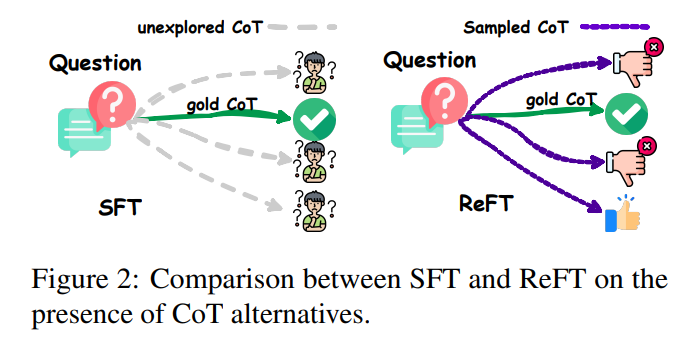
The research proposes ReFT to improve the generalizability of studying LLMs for reasoning, particularly in math problem-solving. ReFT combines SFT with on-line reinforcement studying utilizing the PPO algorithm. The mannequin is first warmed with SFT after which fine-tuned utilizing reinforcement studying, the place a number of reasoning paths are routinely sampled given the query, and rewards are derived from ground-truth solutions. In addition, inference-time methods such as majority voting and re-ranking are mixed with ReFT to increase efficiency additional.
The ReFT technique considerably outperforms SFT concerning reasoning functionality and generalizability for LLMs in math problem-solving. Extensive experiments on GSM8K, MathQA, and SVAMP datasets show the higher efficiency of ReFT over SFT. The efficiency of ReFT may be additional boosted by combining inference-time methods such as majority voting and re-ranking. They use Python packages as CoT prompts, displaying extra correct reasoning steps and vital enhancements over pure language CoT. Previous work on reinforcement studying and reranking has additionally demonstrated higher efficiency over supervised fine-tuning and majority voting.
In conclusion, ReFT stands out as a fine-tuning technique for enhancing fashions in fixing math issues. Unlike SFT), ReFT optimizes a non-differentiable goal by exploring a number of CoT annotations slightly than counting on a single one. Extensive experiments throughout three datasets utilizing two foundational fashions have proven that ReFT surpasses SFT in efficiency and generalization. Models educated with ReFT exhibit compatibility with methods like majority voting and reward mannequin reranking. ReFT outperforms a number of open-source open-source fashions of comparable sizes in math problem-solving, highlighting its effectiveness and sensible worth.
Check out the Paper. All credit score for this analysis goes to the researchers of this challenge. Also, don’t overlook to observe us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our publication..
Don’t Forget to be part of our Telegram Channel
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.