

Recent developments in generative fashions for text-to-image (T2I) duties have led to spectacular leads to producing high-resolution, reasonable photos from textual prompts. However, extending this functionality to text-to-video (T2V) fashions poses challenges as a result of complexities launched by movement. Current T2V fashions face limitations in video length, visible high quality, and reasonable movement technology, primarily because of challenges associated to modeling pure movement, reminiscence, compute necessities, and the necessity for in depth coaching knowledge.
State-of-the-art T2I diffusion fashions excel in synthesizing high-resolution, photo-realistic photos from advanced textual content prompts with versatile picture enhancing capabilities. However, extending these developments to large-scale T2V fashions faces challenges because of movement complexities. Existing T2V fashions typically make use of a cascaded design, the place a base mannequin generates keyframes and subsequent temporal super-resolution (TSR) fashions fill in gaps, however limitations in movement coherence persist.
Researchers from Google Research, Weizmann Institute, Tel-Aviv University, and Technion current Lumiere, a novel text-to-video diffusion mannequin addressing the problem of reasonable, various, and coherent movement synthesis. They introduce a Space-Time U-Net structure that uniquely generates your entire temporal length of a video in a single go, contrasting with current fashions that synthesize distant keyframes adopted by temporal super-resolution. By incorporating spatial and temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion mannequin, Lumiere achieves state-of-the-art text-to-video outcomes, effectively supporting numerous content material creation and video enhancing duties.
Employing a Space-Time U-Net structure, Lumiere effectively processes spatial and temporal dimensions, producing full video clips at a rough decision. Temporal blocks with factorized space-time convolutions and a spotlight mechanisms are included for efficient computation. The mannequin leverages pre-trained text-to-image structure, emphasizing a novel strategy to keep up coherence. Multidiffusion is launched for spatial super-resolution, guaranteeing clean transitions between temporal segments and addressing reminiscence constraints.
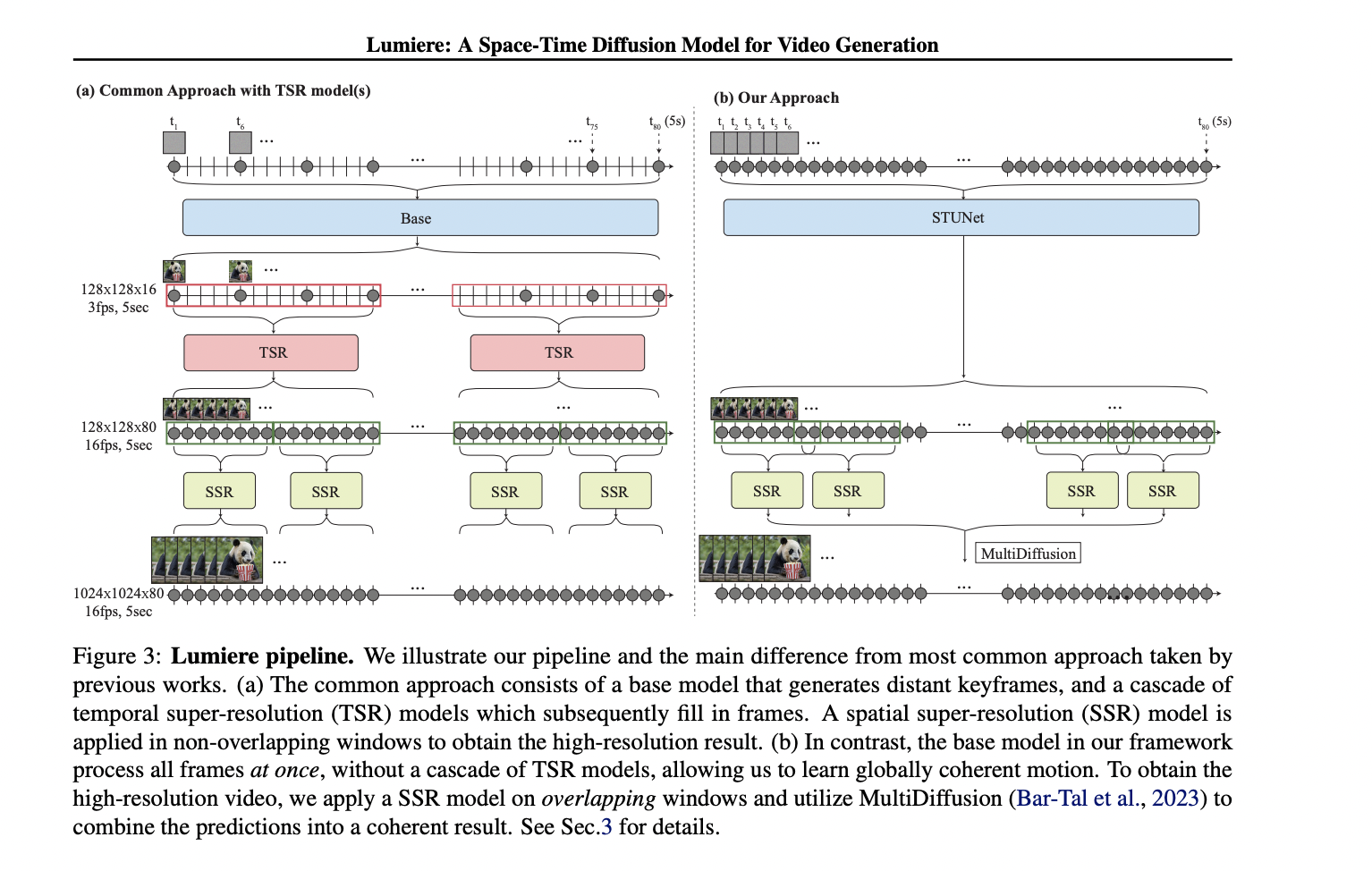
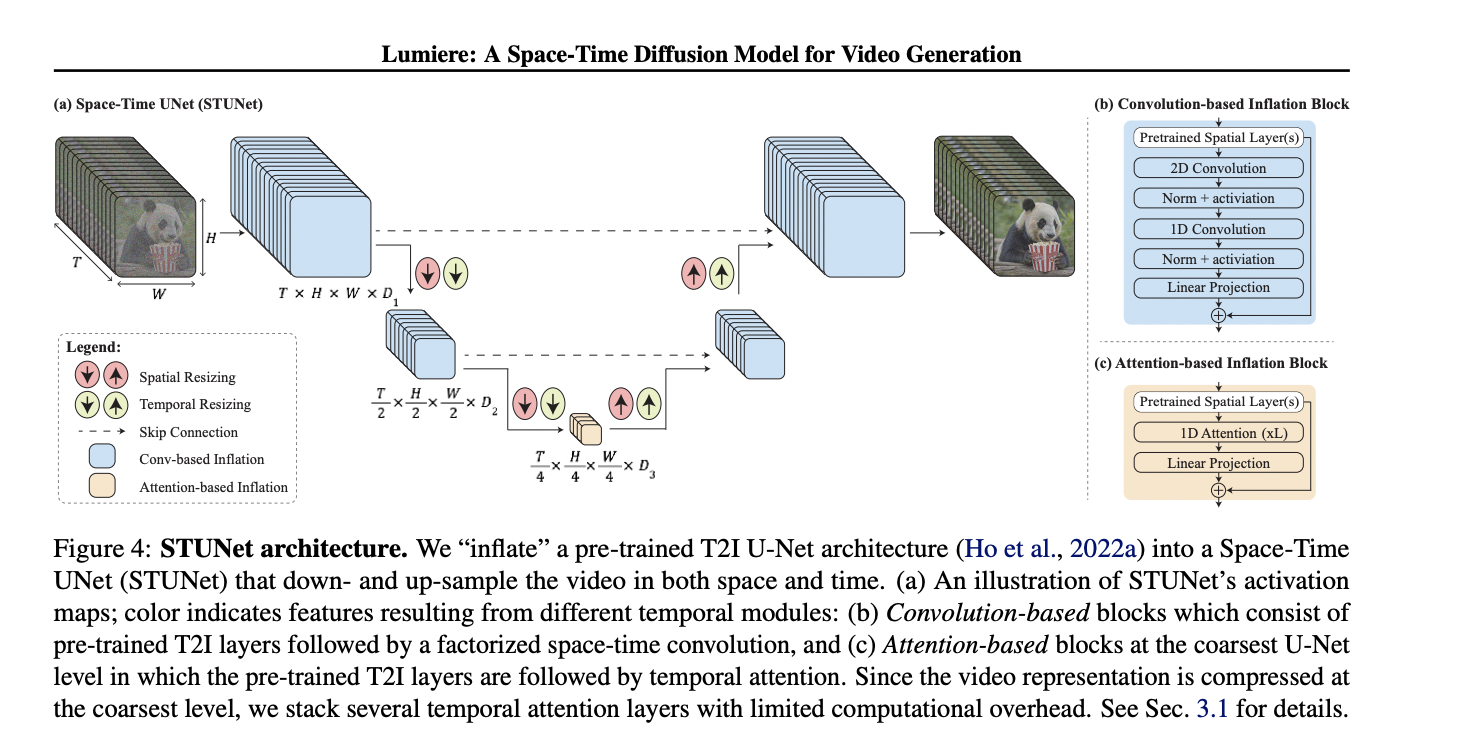
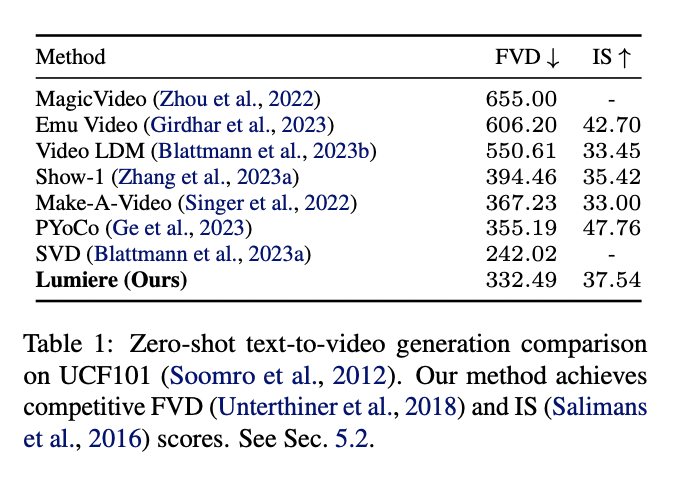
Lumiere surpasses current fashions in video synthesis. Trained on a dataset of 30M 80-frame movies, Lumiere outperforms ImagenVideo, AnimateDiff, and ZeroScope in qualitative and quantitative evaluations. With aggressive Frechet Video Distance and Inception Score in zero-shot testing on UCF101, Lumiere demonstrates superior movement coherence, producing 5-second movies at increased high quality. User research verify Lumiere’s choice over numerous baselines, together with business fashions, highlighting its excellence in visible high quality and alignment with textual content prompts.
To sum up, the researchers from Google Research and different institutes have launched Lumiere, an revolutionary text-to-video technology framework primarily based on a pre-trained text-to-image diffusion mannequin. They addressed the limitation of worldwide coherent movement in current fashions by proposing a space-time U-Net structure. This design, incorporating spatial and temporal down- and up-sampling, allows the direct technology of full-frame-rate video clips. The demonstrated state-of-the-art outcomes spotlight the flexibility of the strategy for numerous purposes, equivalent to image-to-video, video inpainting, and stylized technology.
Check out the Paper and Project. All credit score for this analysis goes to the researchers of this venture. Also, don’t overlook to comply with us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our publication..
Don’t Forget to affix our Telegram Channel
![]()
Asjad is an intern guide at Marktechpost. He is persuing B.Tech in mechanical engineering on the Indian Institute of Technology, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.