
")
The efficiency of multimodal giant Language Models (MLLMs) in visible conditions has been distinctive, gaining unmatched consideration. However, their capacity to unravel visible math issues should nonetheless be totally assessed and comprehended. For this motive, arithmetic usually presents challenges in understanding complicated ideas and deciphering the visible info essential for fixing issues. In instructional contexts and past, deciphering diagrams and illustrations turns into indispensable, particularly when tackling mathematical points.
Frameworks like GeoQA and MathVista have tried to bridge the hole between textual content material and visible interpretation, specializing in geometric queries and broader mathematical ideas. These fashions, together with SPHINX and GPT-4V, have aimed to boost multimodal comprehension by tackling numerous challenges, from geometric problem-solving to understanding complicated diagrams. Despite their advances, a completely built-in method to seamlessly mix textual evaluation with correct visible interpretation within the context of mathematical reasoning stays a frontier but to be totally conquered.
A analysis staff from CUHK MMLab and Shanghai Artificial Intelligence Laboratory has proposed “MATHVERSE,” an modern benchmark designed to carefully consider MLLMs’ capabilities in deciphering visible info inside mathematical issues. This method introduces numerous math issues built-in with diagrams to check fashions’ understanding past textual reasoning.
MATHVERSE engages MLLMs with 2,612 math issues, every outfitted with diagrams to problem visible information processing. Researchers rigorously tailored these issues into six distinct codecs, starting from text-dominant to vision-only, to dissect MLLMs’ multimodal evaluation abilities. Performance evaluation revealed various success; some fashions surprisingly improved by over 5% in accuracy when disadvantaged of visible cues, hinting at a stronger textual than visible reliance. Particularly, GPT-4V demonstrated a balanced proficiency in textual content and imaginative and prescient modalities, providing a complete perception into present MLLMs’ capabilities and limitations in dealing with visible and mathematical queries.
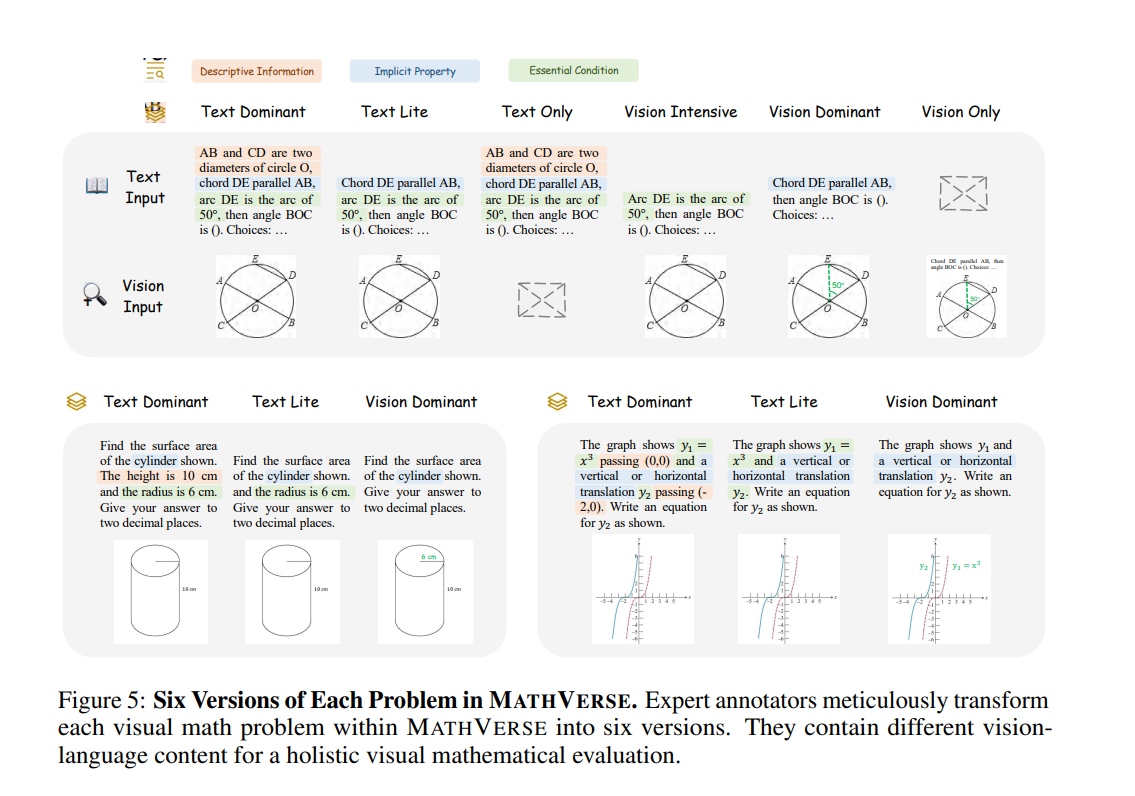
The analysis on MATH VERSE highlighted that, whereas fashions like Qwen-VL-Max and InternLM-XComposer2 skilled a lift in efficiency (over 5% accuracy enhance) with out visible inputs, GPT-4V displayed extra adeptness at integrating visible info, carefully matching human-level efficiency in text-only situations. This variance underscores a reliance on textual content over visuals amongst MLLMs, with GPT-4V rising as a notable exception for its comparative visible comprehension.
In conclusion, the analysis proposes a specialised benchmark referred to as MATHVERSE to evaluate the visible, mathematical problem-solving capability of MLLMs. The findings reveal that almost all current fashions want visible enter to grasp mathematical diagrams and might even carry out higher. This suggests a vital want for extra superior math-specific imaginative and prescient encoders, highlighting the potential future course of MLLM growth.
Check out the Paper and Project. All credit score for this analysis goes to the researchers of this mission. Also, don’t neglect to observe us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our e-newsletter..
Don’t Forget to affix our 39k+ ML SubReddit
![]()
Nikhil is an intern advisor at Marktechpost. He is pursuing an built-in twin diploma in Materials on the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Material Science, he’s exploring new developments and creating alternatives to contribute.