
 Targeted to Run on Mobile Devices")
A promising new growth in synthetic intelligence known as MobileVLM, designed to maximize the potential of cell gadgets, has emerged. This cutting-edge multimodal imaginative and prescient language mannequin (MMVLM) represents a significant development in incorporating AI into frequent know-how since it’s constructed to operate successfully in cell conditions.
Researchers from Meituan Inc., Zhejiang University, and Dalian University of Technology spearheaded the creation of MobileVLM to deal with the difficulties in integrating LLMs with imaginative and prescient fashions for duties like visible query answering and picture captioning, significantly in conditions with restricted assets. The conventional methodology of utilizing giant datasets created a barrier that hindered the event of text-to-video producing fashions. By using regulated and open-source datasets, MobileVLM will get round this and makes it potential to assemble high-performance fashions with out being restricted by giant quantities of knowledge.
The structure of MobileVLM is a fusion of modern design and sensible utility. It contains a visible encoder, a language mannequin tailor-made for edge gadgets, and an environment friendly projector. This projector is essential in aligning graphic and textual content options and is designed to reduce computational prices whereas sustaining spatial data. The mannequin considerably reduces the variety of visible tokens, enhancing the inference velocity with out compromising output high quality.
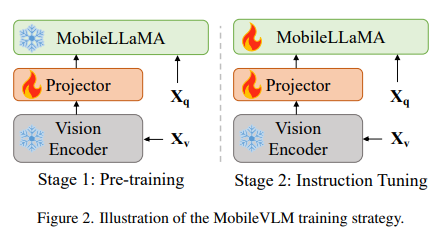
The coaching technique of MobileVLM entails three key phases. Initially, language mannequin basis fashions are pre-trained on a text-only dataset. This is adopted by supervised fine-tuning utilizing multi-turn dialogues between people and ChatGPT. The ultimate stage entails coaching imaginative and prescient giant fashions with multimodal datasets. This complete coaching technique ensures that MobileVLM is environment friendly and strong in its efficiency.
The efficiency of MobileVLM on language understanding and customary sense reasoning benchmarks is noteworthy. It competes favorably with current fashions, demonstrating its efficacy in language processing and reasoning duties. MobileVLM’s efficiency on numerous imaginative and prescient language mannequin benchmarks underscores its potential. Despite its diminished parameters and reliance on restricted coaching knowledge, it achieves outcomes comparable to bigger, extra resource-intensive fashions.
In conclusion, MobileVLM stands out for a number of causes:
- It effectively bridges the hole between giant language and imaginative and prescient fashions, enabling superior multimodal interactions on cell gadgets.
- The modern structure, comprising an environment friendly projector and tailor-made language mannequin, optimizes efficiency and velocity.
- MobileVLM’s coaching course of, involving pre-training, fine-tuning, and utilizing multimodal datasets, contributes to its robustness and adaptableness.
- It demonstrates aggressive efficiency on numerous benchmarks, indicating its potential in real-world functions.
Check out the Paper and Github. All credit score for this analysis goes to the researchers of this mission. Also, don’t neglect to be part of our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, Twitter, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
If you want our work, you’ll love our publication..
![]()
Hello, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Express. I’m at present pursuing a twin diploma on the Indian Institute of Technology, Kharagpur. I’m obsessed with know-how and wish to create new merchandise that make a distinction.