

Whenever somebody talks about synthetic intelligence, the very first thing that involves thoughts is a robotic, an android, or a humanoid that can do issues people do with the identical impact, if not higher. We have all seen such particular miniature robots deployed in numerous fields, for instance, in airports guiding folks to sure retailers, in armed forces to navigate and cope with tough conditions, and at the same time as trackers.
All of these are some superb examples of AI in a more true sense. As with each different AI mannequin, this has some fundamental necessities that have to be happy, for instance, which selection of algorithm, the massive corpus of knowledge to coach on, finetuning, after which deployment.
Now, this kind of drawback is sometimes called the Visual-and-Language-Navigation drawback. Vision and language navigation in synthetic intelligence (AI) refers back to the capability of an AI system to grasp and navigate the world utilizing visible and linguistic data. It combines pc imaginative and prescient, pure language processing, and machine studying strategies to construct clever techniques that can understand graphic scenes, understands textual directions, and navigate bodily environments.
Many fashions, corresponding to CLIP, RecBERT, and PREVALENT, work on these issues, however all of these fashions vastly undergo from two main points.
Limited Data and Data Bias: Training visible and studying techniques require massive quantities of labeled knowledge. However, acquiring such knowledge can be costly, time-consuming, and even impractical in sure domains. Moreover, the provision of numerous and consultant knowledge is essential to keep away from bias within the system’s understanding and decision-making. If the coaching knowledge is biased, it can result in unfair or inaccurate predictions and behaviors.
Generalization: AI techniques must generalize effectively to unseen or novel knowledge. They ought to memorize the coaching knowledge and study underlying ideas and patterns that can be utilized to new examples. Overfitting happens when a mannequin performs effectively on the coaching knowledge however fails to generalize to new knowledge. Achieving strong generalization is a major problem, notably in advanced visible duties that contain variations in lighting situations, viewpoints, and object appearances.
Though many efforts have been proposed to assist the agent study numerous instruction inputs, all these datasets are constructed on the identical 3D room environments from Matterport3D, which solely comprises 60 completely different room environments for brokers’ coaching.
PanoGen, the breakthrough within the AI area, has supplied a powerful answer to this drawback. Now with PanoGen, the shortage of knowledge is solved, and corpus creation and knowledge diversification have additionally been streamlined.
PanoGen is a generative methodology that can create infinite numerous panoramic photographs (environments) primarily based on the textual content. They have collected room descriptions by captioning the room photographs accessible with the Matterport3D dataset and have used SoTA text-to-image mannequin to generate panoramic visions (environments). They then use recursive outpainting over the generated picture to create a constant 360-degree panorama view. The panoramic photos developed share related semantic data conditioning on textual content descriptions, which ensures the co-occurrence of objects within the panorama follows human instinct, and creates sufficient range in room look and format with picture outpainting.
They have talked about that there have been makes an attempt to extend the range of coaching knowledge and enhance the corpus. All of these makes an attempt had been primarily based on mixing scenes from HM3D (Habitat Matterport 3D), which once more brings again the identical difficulty that all of the settings, kind of, are made with Matterport3D.
PanoGen solves this drawback because it can create an infinite quantity of coaching knowledge with as many variations as wanted.
The paper additionally mentions that utilizing the PanoGen strategy, they beat the present SoTA and achieved the brand new SoTA on Room-to-Room, Room-for-Room, and CVDN datasets.
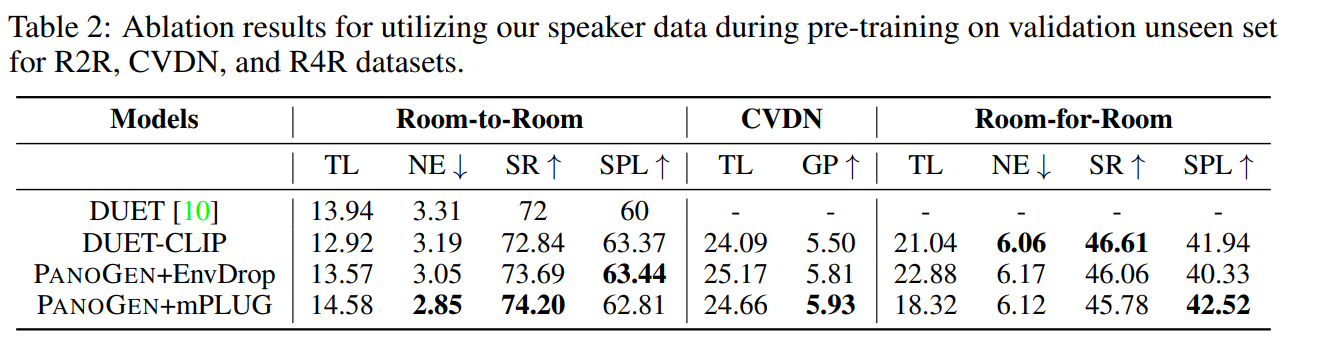
Conclusively, PanoGen is a breakthrough improvement that addresses the important thing challenges in Visual-and-Language Navigation issues. With the power to generate limitless coaching samples with many variations, PanoGen opens up new prospects for AI techniques to grasp and navigate the actual world as people do. The strategy’s exceptional capability to surpass the SoTA highlights its potential to revolutionize AI-driven VLN duties.
Check Out The Paper, Code, and Project. Don’t overlook to hitch our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra. If you will have any questions concerning the above article or if we missed something, be happy to e-mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Anant is a Computer science engineer at the moment working as a knowledge scientist with expertise in Finance and AI merchandise as a service. He is eager to construct AI-powered options that create higher knowledge factors and remedy every day life issues in an impactful and environment friendly manner.