
 Series Developed Upon SPHINX")
The emergence of Multimodality Large Language Models (MLLMs), equivalent to GPT-4 and Gemini, has sparked important curiosity in combining language understanding with varied modalities like imaginative and prescient. This fusion gives potential for numerous purposes, from embodied intelligence to GUI brokers. Despite the speedy improvement of open-source MLLMs like BLIP and LLaMA-Adapter, their efficiency may very well be improved by extra coaching knowledge and mannequin parameters. While some excel in pure picture understanding, they need assistance with duties requiring specialised data. Moreover, the present mannequin sizes might not be appropriate for cellular deployment, necessitating the exploration of smaller and extra parameter-rich architectures for broader adoption and improved efficiency.
Researchers from Shanghai AI Laboratory, MMLab, CUHK, Rutgers University, and the University of California, Los Angeles, have developed SPHINX-X, a complicated MLLM collection constructed upon the SPHINX framework. Enhancements embody streamlining structure by eradicating redundant visible encoders, optimizing coaching effectivity with skip tokens for absolutely padded sub-images, and transitioning to a one-stage coaching paradigm. SPHINX-X leverages a various multimodal dataset, augmented with curated OCR and Set-of-Mark knowledge, and is educated throughout varied base LLMs, providing a variety of parameter sizes and multilingual capabilities. Benchmarked outcomes underscore SPHINX-X’s superior generalization throughout duties, addressing earlier MLLM limitations whereas optimizing for environment friendly, large-scale multimodal coaching.
Recent developments in LLMs have leveraged Transformer architectures, notably exemplified by GPT-3’s 175B parameters. Other fashions like PaLM, OPT, BLOOM, and LLaMA have adopted go well with, with improvements like Mistral’s window consideration and Mixtral’s sparse MoE layers. Concurrently, bilingual LLMs like Qwen and Baichuan have emerged, whereas TinyLlama and Phi-2 concentrate on parameter discount for edge deployment. Meanwhile, MLLMs combine non-text encoders for visible understanding, with fashions like BLIP, Flamingo, and LLaMA-Adapter collection pushing the boundaries of vision-language fusion. Fine-grained MLLMs like Shikra and VisionLLM excel in particular duties, whereas others prolong LLMs to numerous modalities.
The examine revisits the design rules of SPHINX. It proposes three enhancements to SPHINX-X, together with the brevity of visible encoders, learnable skip tokens for ineffective optical alerts, and simplified one-stage coaching. The researchers assemble a large-scale multi-modality dataset masking language, imaginative and prescient, and vision-language duties and enrich it with curated OCR intensive and Set-of-Mark datasets. The SPHINX-X household of MLLMs is educated over completely different base LLMs, together with TinyLlama-1.1B, InternLM2-7B, LLaMA2-13B, and Mixtral-8×7B, to acquire a spectrum of MLLMs with various parameter sizes and multilingual capabilities.
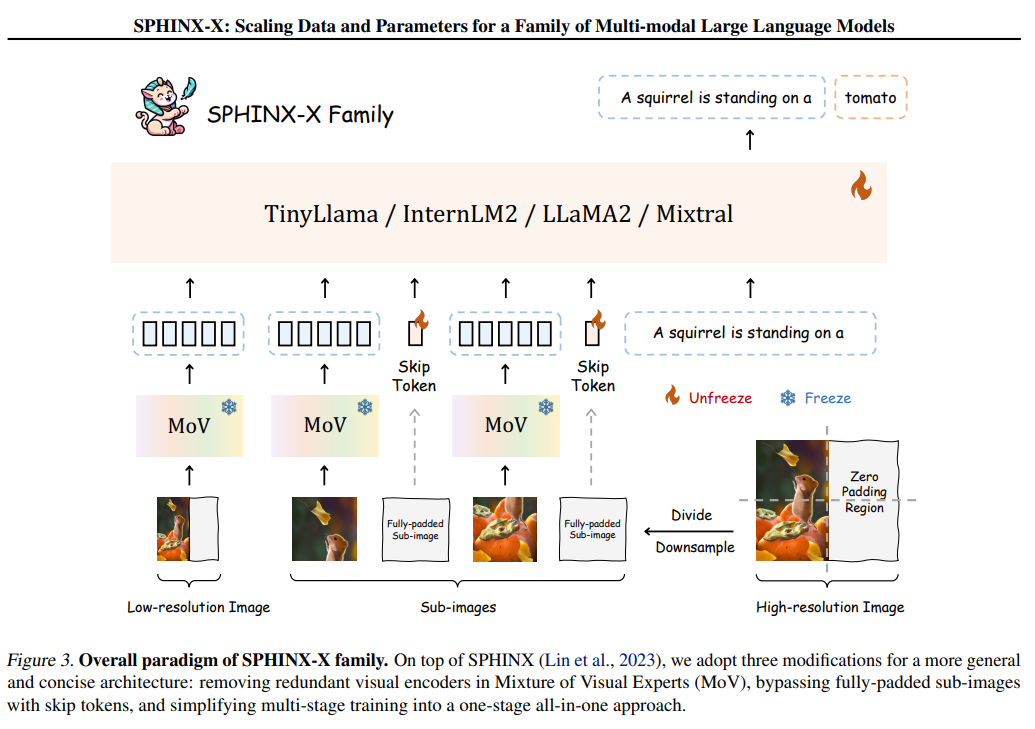
The SPHINX-X MLLMs reveal state-of-the-art efficiency throughout varied multi-modal duties, together with mathematical reasoning, complicated scene understanding, low-level imaginative and prescient duties, visible high quality evaluation, and resilience when going through illusions. Comprehensive benchmarking reveals a powerful correlation between the multi-modal efficiency of the MLLMs and the scales of knowledge and parameters utilized in coaching. The examine presents the efficiency of SPHINX-X on curated benchmarks equivalent to HallusionBench, AesBench, ScreenSpot, and MMVP, showcasing its capabilities in language hallucination, visible phantasm, aesthetic notion, GUI factor localization, and visible understanding.
In conclusion, SPHINX-X considerably advances MLLMs, constructing upon the SPHINX framework. Through enhancements in structure, coaching effectivity, and dataset enrichment, SPHINX-X reveals superior efficiency and generalization in comparison with the unique mannequin. Scaling up parameters additional amplifies its multi-modal understanding capabilities. The launch of code and fashions on GitHub fosters replication and additional analysis. With enhancements together with streamlined structure and a complete dataset, SPHINX-X gives a strong platform for multi-purpose, multi-modal instruction tuning throughout a variety of parameter scales, shedding gentle on future MLLM analysis endeavors.
Check out the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Also, don’t overlook to comply with us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our e-newsletter..
Don’t Forget to affix our Telegram Channel
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.