

Artificial intelligence (AI) giant language fashions (LLMs) can generate textual content, translate languages, write numerous types of artistic materials, and present useful solutions to your questions. However, LLMs have a couple of points, reminiscent of the truth that they’re educated on giant datasets of textual content and code that could comprise biases. The outcomes produced by LLMs could replicate these prejudices, reinforcing destructive stereotypes and spreading false info. Sometimes, LLMs will produce writing that has no foundation in actuality. Hallucination describes these experiences. Misinterpretation and misguided inferences may consequence from studying hallucinatory textual content. It takes work to get a deal with on how LLMs perform inside. Because of this, it’s laborious to know the reasoning behind the fashions’ actions. This could trigger points in contexts the place openness and duty are essential, reminiscent of the medical and monetary sectors. Training and deploying LLMs takes a considerable amount of computing energy. They could turn out to be inaccessible to many smaller corporations and nonprofits. Spam, phishing emails, and pretend information are all examples of dangerous info that will be generated utilizing LLMs. Users and companies alike could also be put at risk due to this.
Researchers from NVIDIA have collaborated with business leaders like Meta, Anyscale, Cohere, Deci, Grammarly, Mistral AI, MosaicML (now a part of Databricks), OctoML, Tabnine, and Together AI to hurry up and good LLM inference. These enhancements might be included in the forthcoming open-source NVIDIA TensorRT-LLM software program model. TensorRT-LLM is a deep studying compiler that makes use of NVIDIA GPUs to supply state-of-the-art efficiency because of its optimized kernels, pre-and post-processing phases, and multi-GPU/multi-node communication primitives. Developers can experiment with new LLMs without having in-depth familiarity with C++ or NVIDIA CUDA, offering top-notch efficiency and fast customization choices. With its open-source, modular Python API, TensorRT-LLM makes it easy to outline, optimize, and execute new architectures and enhancements as LLMs develop.
By leveraging NVIDIA’s newest information middle GPUs, TensorRT-LLM hopes to extend LLM throughput whereas decreasing bills enormously. For creating, optimizing, and operating LLMs for inference in manufacturing, it supplies an easy, open-source Python API that encapsulates the TensorRT Deep Learning Compiler, optimized kernels from FasterTransformer, pre-and post-processing, and multi-GPU/multi-node communication.
TensorRT-LLM permits for a greater variety of LLM functions. Now that we have now 70-billion-parameter fashions like Meta’s Llama 2 and Falcon 180B, a cookie-cutter method is not sensible. The real-time efficiency of such fashions is often dependent on multi-GPU configurations and complicated coordination. By offering tensor parallelism that distributes weight matrices amongst gadgets, TensorRT-LLM streamlines this course of and eliminates the want for guide fragmentation and rearrangement on the a part of builders.
The in-flight batching optimization is one other notable function tailor-made to handle the extraordinarily fluctuating workloads typical of LLM functions successfully. This perform allows dynamic parallel execution, which maximizes GPU utilization for duties like question-and-answer engagements in chatbots and doc summarization. Given the growing dimension and scope of AI implementations, companies can anticipate diminished complete value of possession (TCO).
The outcomes when it comes to efficiency are mind-blowing. Performance on benchmarks reveals an 8x achieve in duties like article summarization when utilizing TensorRT-LLM with NVIDIA H100 in comparison with the A100.
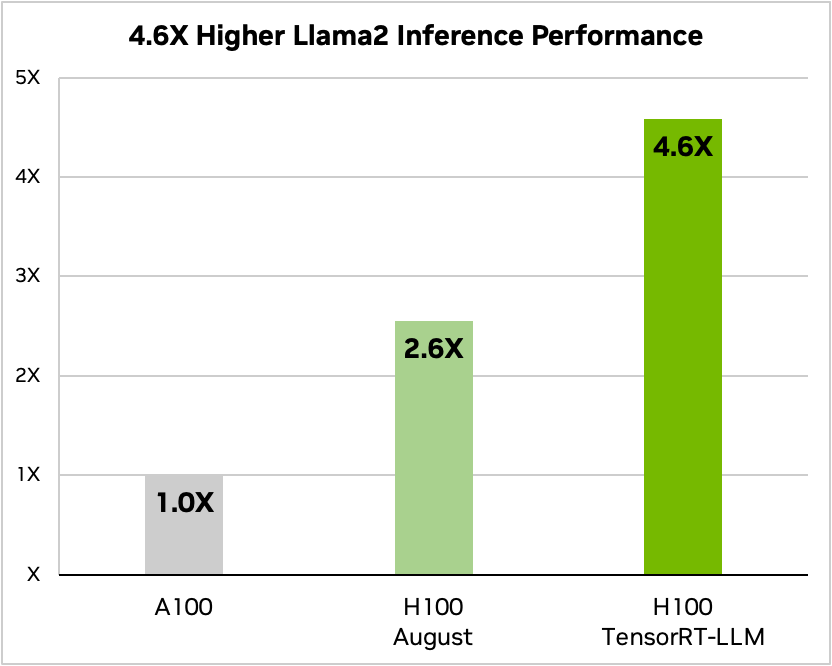
TensorRT-LLM can improve inference efficiency by 4.6x in comparison with A100 GPUs on Llama 2, a extensively used language mannequin launched not too long ago by Meta and utilized by many companies wishing to implement generative AI.
Text summarization, variable I/O size, CNN / DailyMail dataset | A100 FP16 PyTorch keen mode| H100 FP8 | H100 FP8, in-flight batching, TensorRT-LLM | Image Source: https://developer.nvidia.com/weblog/nvidia-tensorrt-llm-supercharges-large-language-model-inference-on-nvidia-h100-gpus/
To summarize, LLMs are creating rapidly. Each day brings a brand new addition to the ever-expanding ecosystem of mannequin designs. As a consequence, bigger fashions open up new prospects and use instances, boosting adoption in each sector. The information middle is evolving on account of LLM inference. TCO is improved for companies on account of greater efficiency with greater precision. Better shopper experiences, made potential via mannequin modifications, result in elevated gross sales and earnings. There are quite a few further components to contemplate when planning inference deployment initiatives to get the most out of state-of-the-art LLMs. Rarely does optimization happen by itself. Users ought to take into consideration parallelism, end-to-end pipelines, and refined scheduling strategies as they carry out fine-tuning. They want a pc system that can deal with information of various levels of precision with out sacrificing accuracy. TensorRT-LLM is a simple, open-source Python API for creating, optimizing, and operating LLMs for inference in manufacturing. It options TensorRT’s Deep Learning Compiler, optimized kernels, pre-and post-processing, and multi-GPU/multi-node communication.
Also, don’t overlook to affix our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you want our work, you’ll love our e-newsletter..
References:
- https://developer.nvidia.com/weblog/nvidia-tensorrt-llm-supercharges-large-language-model-inference-on-nvidia-h100-gpus/
- https://developer.nvidia.com/tensorrt-llm-early-access
![]()
Prathamesh Ingle is a Mechanical Engineer and works as a Data Analyst. He can be an AI practitioner and licensed Data Scientist with an curiosity in functions of AI. He is keen about exploring new applied sciences and developments with their real-life functions