

Medicine is an inherently multimodal self-discipline. When offering care, clinicians routinely interpret information from a variety of modalities together with medical pictures, medical notes, lab assessments, digital well being data, genomics, and extra. Over the final decade or so, AI techniques have achieved expert-level efficiency on particular duties inside particular modalities — some AI techniques processing CT scans, whereas others analyzing excessive magnification pathology slides, and nonetheless others trying to find uncommon genetic variations. The inputs to those techniques are usually complicated information comparable to pictures, they usually sometimes present structured outputs, whether or not within the type of discrete grades or dense picture segmentation masks. In parallel, the capacities and capabilities of huge language fashions (LLMs) have change into so superior that they’ve demonstrated comprehension and experience in medical data by each decoding and responding in plain language. But how will we carry these capabilities collectively to construct medical AI techniques that may leverage data from all these sources?
In right now’s weblog publish, we define a spectrum of approaches to bringing multimodal capabilities to LLMs and share some thrilling outcomes on the tractability of constructing multimodal medical LLMs, as described in three current analysis papers. The papers, in flip, define the best way to introduce de novo modalities to an LLM, the best way to graft a state-of-the-art medical imaging basis mannequin onto a conversational LLM, and first steps in the direction of constructing a very generalist multimodal medical AI system. If efficiently matured, multimodal medical LLMs would possibly function the premise of recent assistive applied sciences spanning skilled drugs, medical analysis, and client functions. As with our prior work, we emphasize the necessity for cautious analysis of those applied sciences in collaboration with the medical neighborhood and healthcare ecosystem.
A spectrum of approaches
Several strategies for constructing multimodal LLMs have been proposed in current months [1, 2, 3], and little doubt new strategies will proceed to emerge for a while. For the aim of understanding the alternatives to carry new modalities to medical AI techniques, we’ll think about three broadly outlined approaches: software use, mannequin grafting, and generalist techniques.
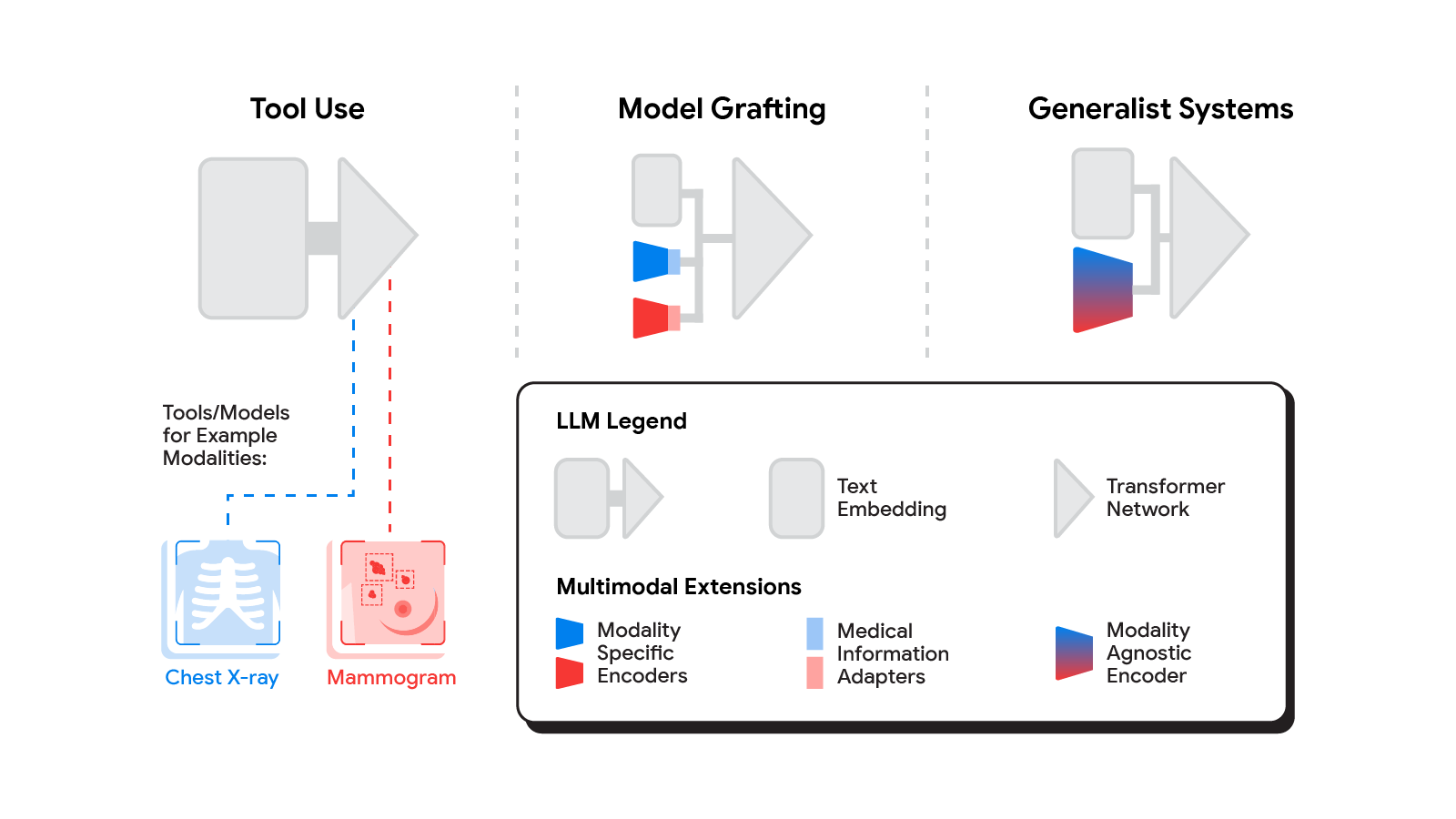 |
| The spectrum of approaches to constructing multimodal LLMs vary from having the LLM use current instruments or fashions, to leveraging domain-specific elements with an adapter, to joint modeling of a multimodal mannequin. |
Tool use
In the software use strategy, one central medical LLM outsources evaluation of knowledge in numerous modalities to a set of software program subsystems independently optimized for these duties: the instruments. The frequent mnemonic instance of software use is instructing an LLM to make use of a calculator reasonably than do arithmetic by itself. In the medical area, a medical LLM confronted with a chest X-ray may ahead that picture to a radiology AI system and combine that response. This may very well be achieved through software programming interfaces (APIs) provided by subsystems, or extra fancifully, two medical AI techniques with totally different specializations partaking in a dialog.
This strategy has some vital advantages. It permits most flexibility and independence between subsystems, enabling well being techniques to combine and match merchandise between tech suppliers primarily based on validated efficiency traits of subsystems. Moreover, human-readable communication channels between subsystems maximize auditability and debuggability. That stated, getting the communication proper between unbiased subsystems will be tough, narrowing the knowledge switch, or exposing a danger of miscommunication and data loss.
Model grafting
A extra built-in strategy could be to take a neural community specialised for every related area, and adapt it to plug immediately into the LLM — grafting the visible mannequin onto the core reasoning agent. In distinction to software use the place the particular software(s) used are decided by the LLM, in mannequin grafting the researchers might select to make use of, refine, or develop particular fashions throughout improvement. In two current papers from Google Research, we present that that is in truth possible. Neural LLMs sometimes course of textual content by first mapping phrases right into a vector embedding area. Both papers construct on the thought of mapping information from a brand new modality into the enter phrase embedding area already acquainted to the LLM. The first paper, “Multimodal LLMs for health grounded in individual-specific data”, exhibits that bronchial asthma danger prediction within the UK Biobank will be improved if we first practice a neural community classifier to interpret spirograms (a modality used to evaluate respiratory potential) after which adapt the output of that community to function enter into the LLM.
The second paper, “ELIXR: Towards a general purpose X-ray artificial intelligence system through alignment of large language models and radiology vision encoders”, takes this similar tack, however applies it to full-scale picture encoder fashions in radiology. Starting with a basis mannequin for understanding chest X-rays, already proven to be a superb foundation for constructing a wide range of classifiers on this modality, this paper describes coaching a light-weight medical data adapter that re-expresses the highest layer output of the muse mannequin as a sequence of tokens within the LLM’s enter embeddings area. Despite fine-tuning neither the visible encoder nor the language mannequin, the ensuing system shows capabilities it wasn’t educated for, together with semantic search and visible query answering.
 |
| Our strategy to grafting a mannequin works by coaching a medical data adapter that maps the output of an current or refined picture encoder into an LLM-understandable type. |
Model grafting has an a variety of benefits. It makes use of comparatively modest computational sources to coach the adapter layers however permits the LLM to construct on current highly-optimized and validated fashions in every information area. The modularization of the issue into encoder, adapter, and LLM elements may also facilitate testing and debugging of particular person software program elements when growing and deploying such a system. The corresponding disadvantages are that the communication between the specialist encoder and the LLM is not human readable (being a sequence of excessive dimensional vectors), and the grafting process requires constructing a brand new adapter for not simply each domain-specific encoder, but in addition each revision of every of these encoders.
Generalist techniques
The most radical strategy to multimodal medical AI is to construct one built-in, absolutely generalist system natively able to absorbing data from all sources. In our third paper on this space, “Towards Generalist Biomedical AI”, reasonably than having separate encoders and adapters for every information modality, we construct on PaLM-E, a not too long ago printed multimodal mannequin that’s itself a mix of a single LLM (PaLM) and a single imaginative and prescient encoder (ViT). In this arrange, textual content and tabular information modalities are lined by the LLM textual content encoder, however now all different information are handled as a picture and fed to the imaginative and prescient encoder.
 |
| Med-PaLM M is a big multimodal generative mannequin that flexibly encodes and interprets biomedical information together with medical language, imaging, and genomics with the identical mannequin weights. |
We specialize PaLM-E to the medical area by fine-tuning the entire set of mannequin parameters on medical datasets described within the paper. The ensuing generalist medical AI system is a multimodal model of Med-PaLM that we name Med-PaLM M. The versatile multimodal sequence-to-sequence structure permits us to interleave numerous varieties of multimodal biomedical data in a single interplay. To the very best of our data, it’s the first demonstration of a single unified mannequin that may interpret multimodal biomedical information and deal with a various vary of duties utilizing the identical set of mannequin weights throughout all duties (detailed evaluations within the paper).
This generalist-system strategy to multimodality is each essentially the most bold and concurrently most elegant of the approaches we describe. In precept, this direct strategy maximizes flexibility and data switch between modalities. With no APIs to keep up compatibility throughout and no proliferation of adapter layers, the generalist strategy has arguably the best design. But that very same magnificence can also be the supply of a few of its disadvantages. Computational prices are sometimes greater, and with a unitary imaginative and prescient encoder serving a variety of modalities, area specialization or system debuggability may endure.
The actuality of multimodal medical AI
To benefit from AI in drugs, we’ll want to mix the energy of knowledgeable techniques educated with predictive AI with the pliability made potential by generative AI. Which strategy (or mixture of approaches) will likely be most helpful within the discipline will depend on a large number of as-yet unassessed elements. Is the pliability and ease of a generalist mannequin extra priceless than the modularity of mannequin grafting or software use? Which strategy provides the best high quality outcomes for a selected real-world use case? Is the popular strategy totally different for supporting medical analysis or medical training vs. augmenting medical apply? Answering these questions would require ongoing rigorous empirical analysis and continued direct collaboration with healthcare suppliers, medical establishments, authorities entities, and healthcare business companions broadly. We anticipate finding the solutions collectively.