

In current years, diffusion fashions have proven nice success in text-to-image generation, attaining excessive picture high quality, improved inference efficiency, and increasing our artistic inspiration. Nevertheless, it’s nonetheless difficult to effectively management the generation, particularly with situations which are tough to explain with textual content.
Today, we announce MediaPipe diffusion plugins, which allow controllable text-to-image generation to be run on-device. Expanding upon our prior work on GPU inference for on-device massive generative fashions, we introduce new low-cost options for controllable text-to-image generation that may be plugged into current diffusion fashions and their Low-Rank Adaptation (LoRA) variants.
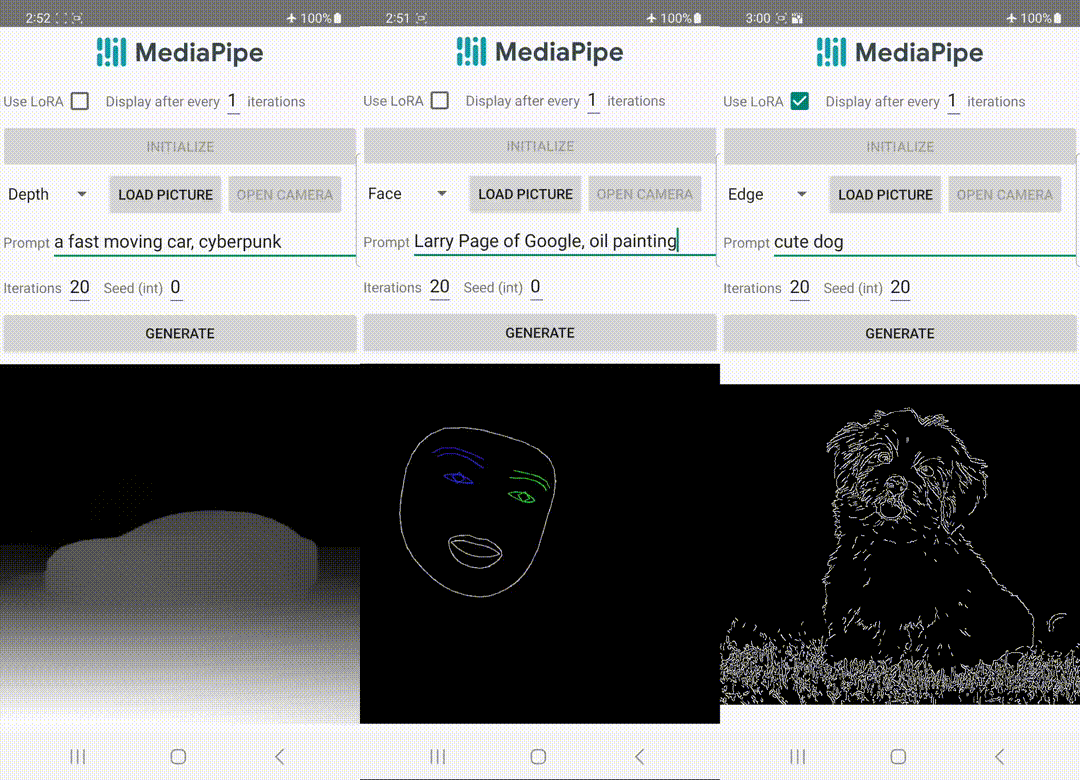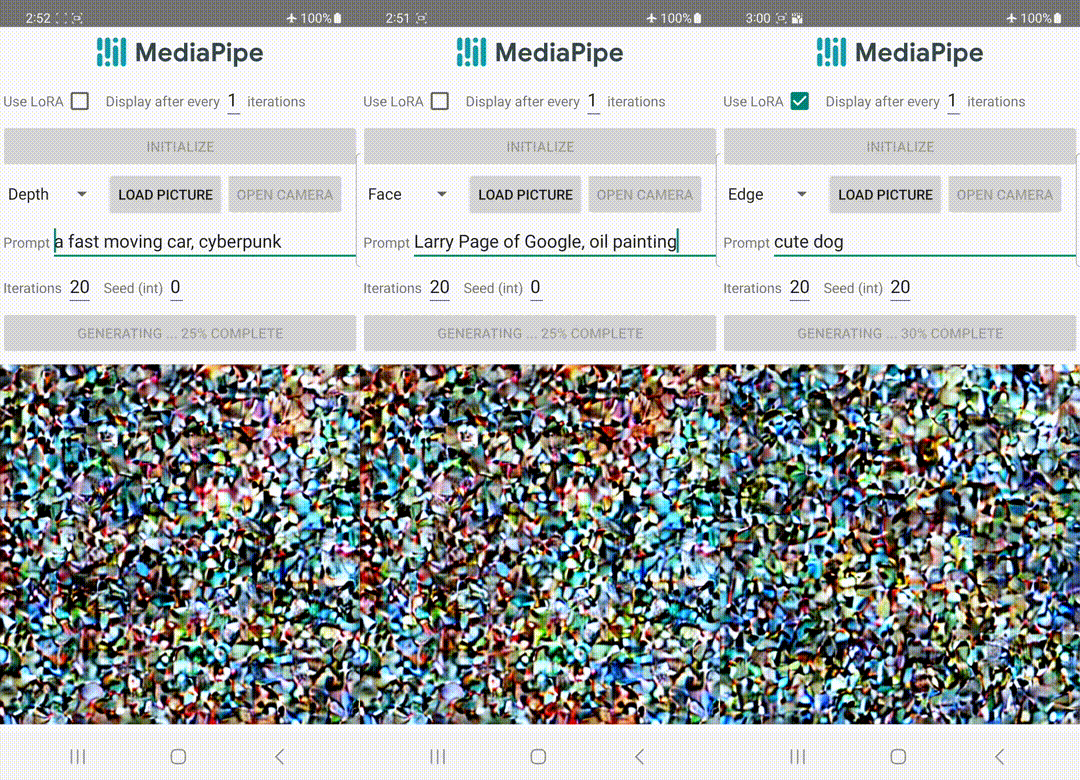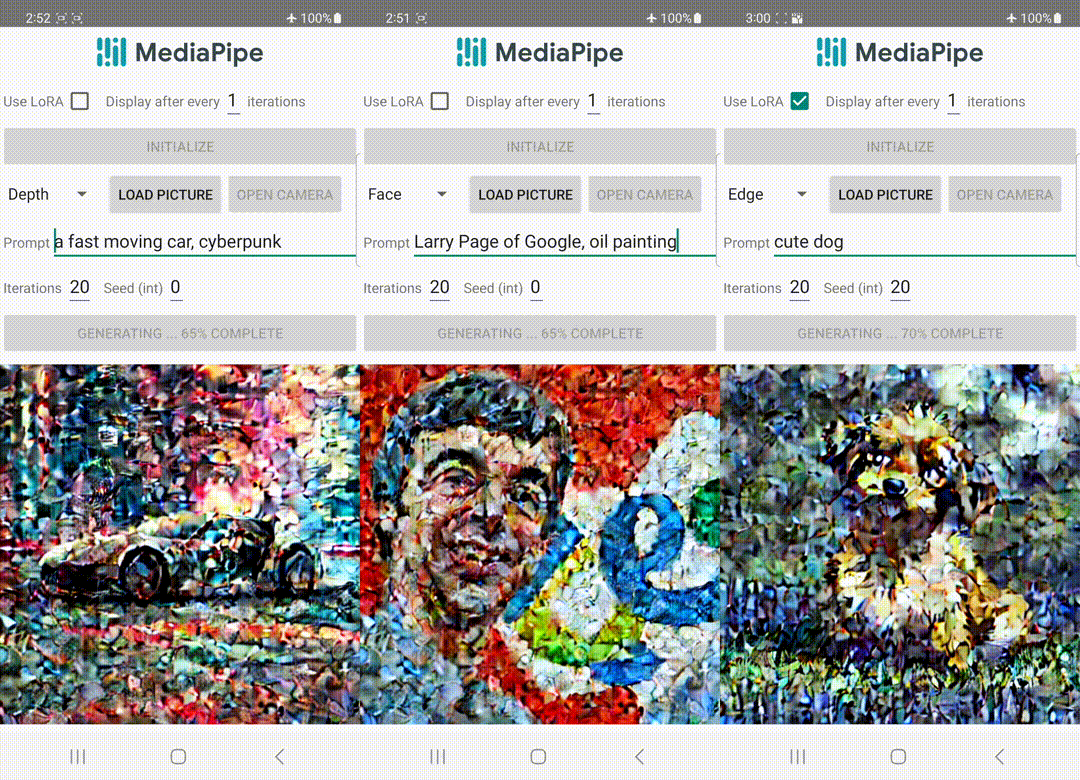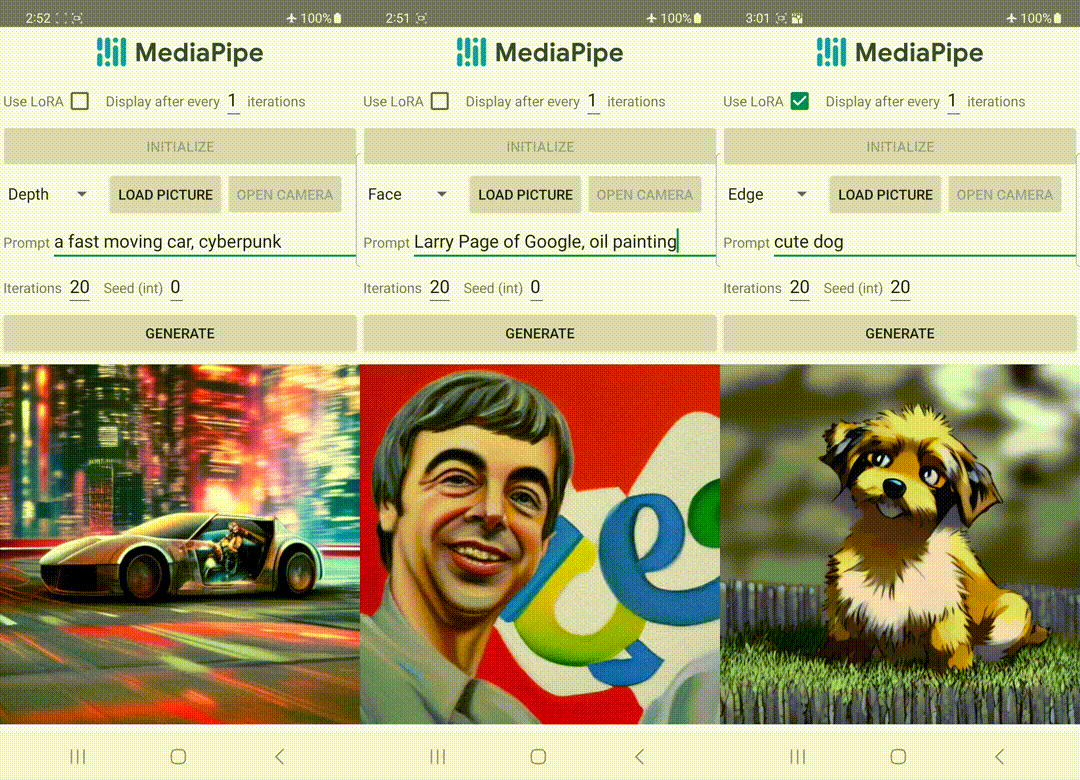 |
| Text-to-image generation with management plugins working on-device. |
Background
With diffusion fashions, picture generation is modeled as an iterative denoising course of. Starting from a noise picture, at every step, the diffusion mannequin step by step denoises the picture to disclose a picture of the goal idea. Research reveals that leveraging language understanding through textual content prompts can enormously enhance picture generation. For text-to-image generation, the textual content embedding is linked to the mannequin through cross-attention layers. Yet, some data is tough to explain by textual content prompts, e.g., the place and pose of an object. To tackle this drawback, researchers add extra fashions into the diffusion to inject management data from a situation picture.
Common approaches for managed text-to-image generation embody Plug-and-Play, ControlNet, and T2I Adapter. Plug-and-Play applies a extensively used denoising diffusion implicit mannequin (DDIM) inversion strategy that reverses the generation course of ranging from an enter picture to derive an preliminary noise enter, after which employs a replica of the diffusion mannequin (860M parameters for Stable Diffusion 1.5) to encode the situation from an enter picture. Plug-and-Play extracts spatial options with self-attention from the copied diffusion, and injects them into the text-to-image diffusion. ControlNet creates a trainable copy of the encoder of a diffusion mannequin, which connects through a convolution layer with zero-initialized parameters to encode conditioning data that’s conveyed to the decoder layers. However, in consequence, the dimensions is massive, half that of the diffusion mannequin (430M parameters for Stable Diffusion 1.5). T2I Adapter is a smaller community (77M parameters) and achieves comparable results in controllable generation. T2I Adapter solely takes the situation picture as enter, and its output is shared throughout all diffusion iterations. Yet, the adapter mannequin is just not designed for transportable units.
The MediaPipe diffusion plugins
To make conditioned generation environment friendly, customizable, and scalable, we design the MediaPipe diffusion plugin as a separate community that’s:
- Plugable: It might be simply linked to a pre-trained base mannequin.
- Trained from scratch: It doesn’t use pre-trained weights from the bottom mannequin.
- Portable: It runs outdoors the bottom mannequin on cell units, with negligible value in comparison with the bottom mannequin inference.
| Method | Parameter Size | Plugable | From Scratch | Portable | ||||
| Plug-and-Play | 860M* | ✔️ | ❌ | ❌ | ||||
| ControlNet | 430M* | ✔️ | ❌ | ❌ | ||||
| T2I Adapter | 77M | ✔️ | ✔️ | ❌ | ||||
| MediaPipe Plugin | 6M | ✔️ | ✔️ | ✔️ |
| Comparison of Plug-and-Play, ControlNet, T2I Adapter, and the MediaPipe diffusion plugin. * The quantity varies relying on the particulars of the diffusion mannequin. |
The MediaPipe diffusion plugin is a transportable on-device mannequin for text-to-image generation. It extracts multiscale options from a conditioning picture, that are added to the encoder of a diffusion mannequin at corresponding ranges. When connecting to a text-to-image diffusion mannequin, the plugin mannequin can present an additional conditioning sign to the picture generation. We design the plugin community to be a light-weight mannequin with solely 6M parameters. It makes use of depth-wise convolutions and inverted bottlenecks from MobileNetv2 for quick inference on cell units.
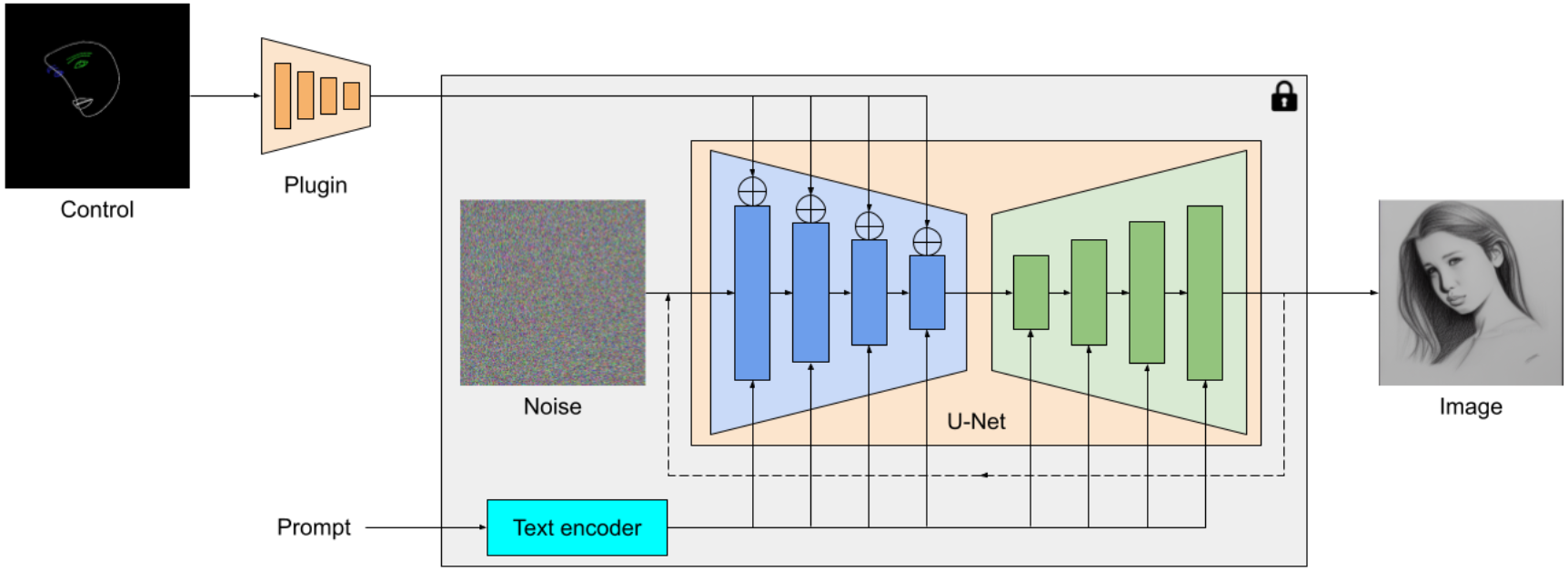 |
| Overview of the MediaPipe diffusion mannequin plugin. The plugin is a separate community, whose output might be plugged right into a pre-trained text-to-image generation mannequin. Features extracted by the plugin are utilized to the related downsampling layer of the diffusion mannequin (blue). |
Unlike ControlNet, we inject the identical management options in all diffusion iterations. That is, we solely run the plugin as soon as for one picture generation, which saves computation. We illustrate some intermediate outcomes of a diffusion course of under. The management is efficient at each diffusion step and permits managed generation even at early steps. More iterations enhance the alignment of the picture with the textual content immediate and generate extra element.
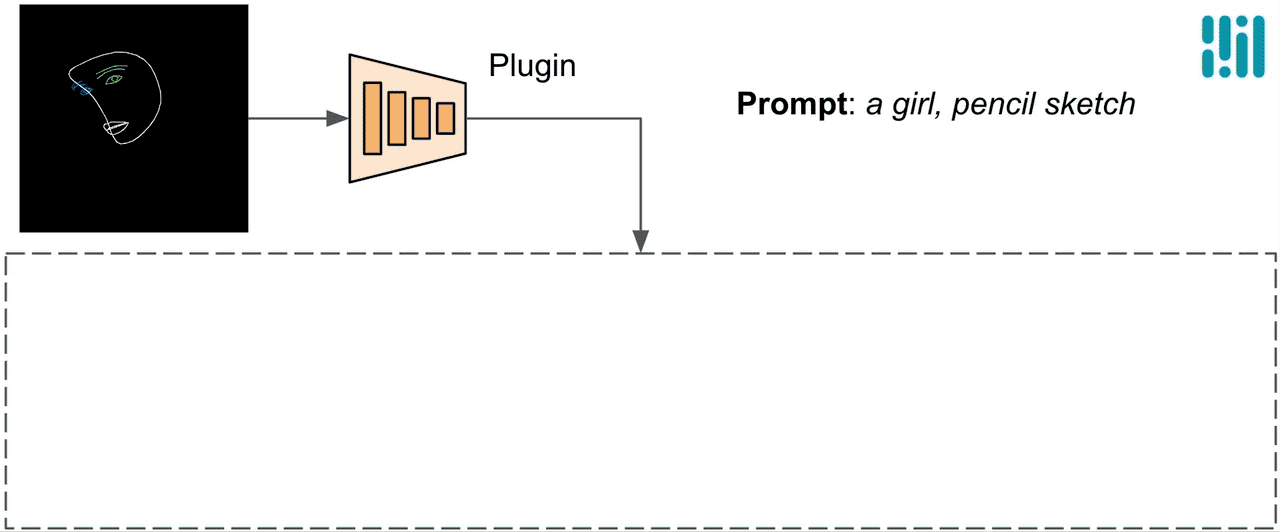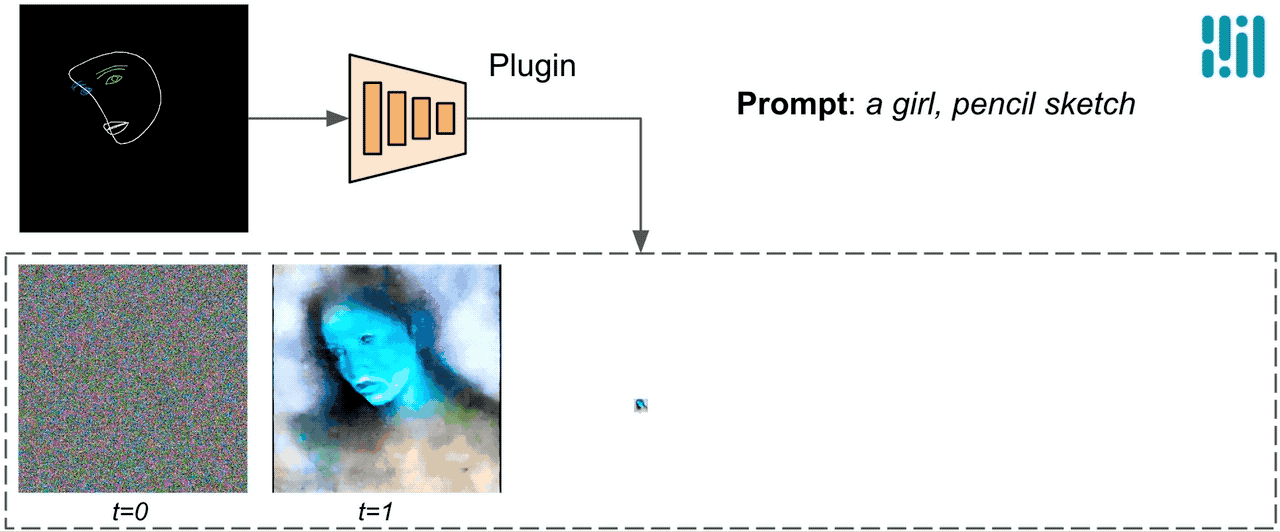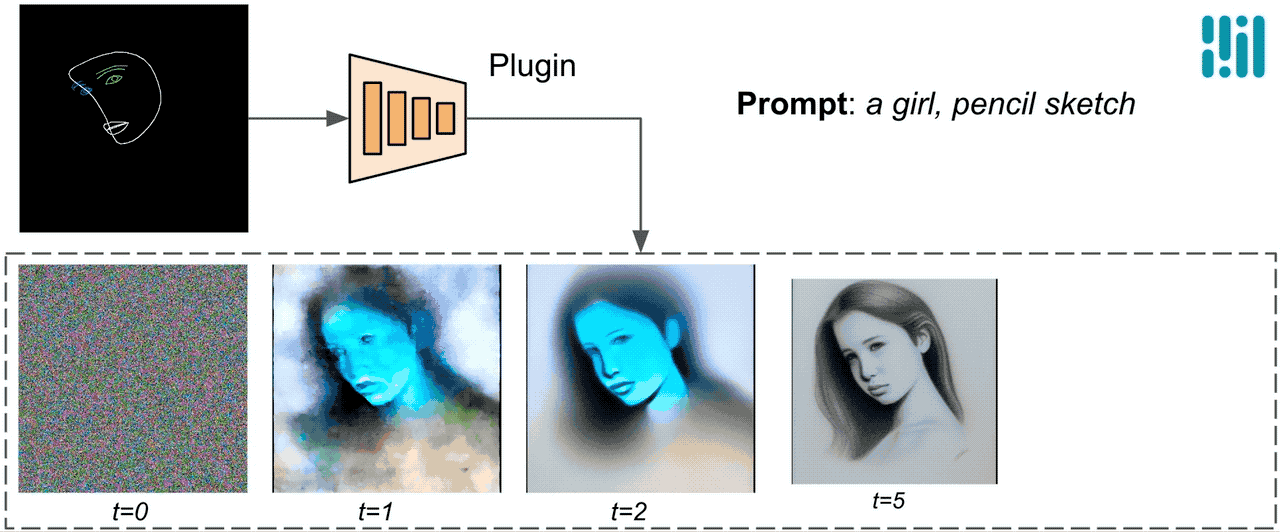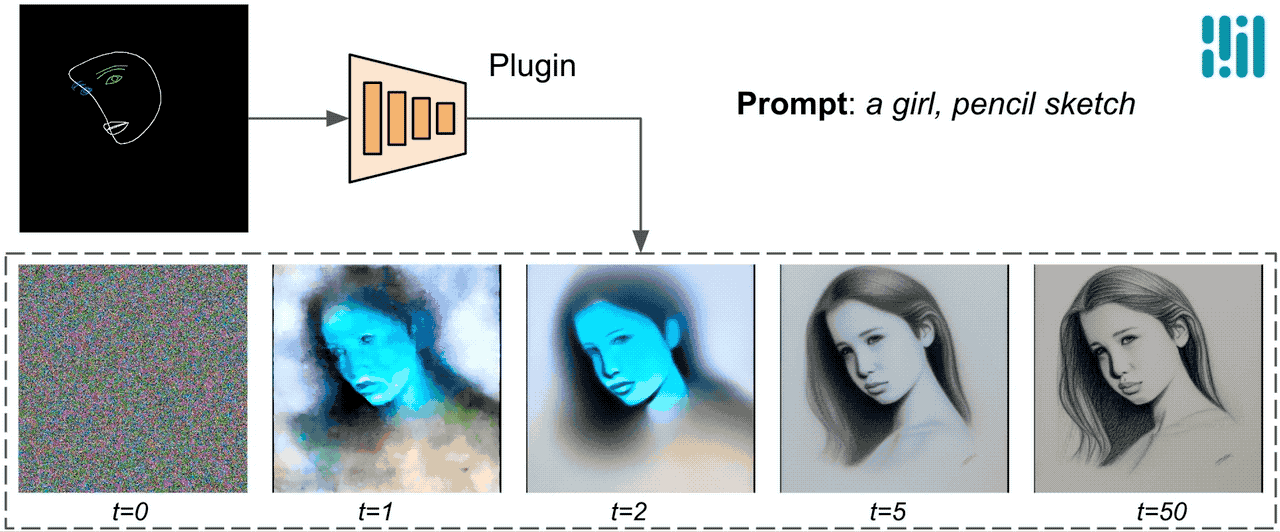 |
| Illustration of the generation course of utilizing the MediaPipe diffusion plugin. |
Examples
In this work, we developed plugins for a diffusion-based text-to-image generation mannequin with MediaPipe Face Landmark, MediaPipe Holistic Landmark, depth maps, and Canny edge. For every process, we choose about 100K photographs from a web-scale image-text dataset, and compute management indicators utilizing corresponding MediaPipe options. We use refined captions from PaLI for coaching the plugins.
Face Landmark
The MediaPipe Face Landmarker process computes 478 landmarks (with consideration) of a human face. We use the drawing utils in MediaPipe to render a face, together with face contour, mouth, eyes, eyebrows, and irises, with totally different colours. The following desk reveals randomly generated samples by conditioning on face mesh and prompts. As a comparability, each ControlNet and Plugin can management text-to-image generation with given situations.
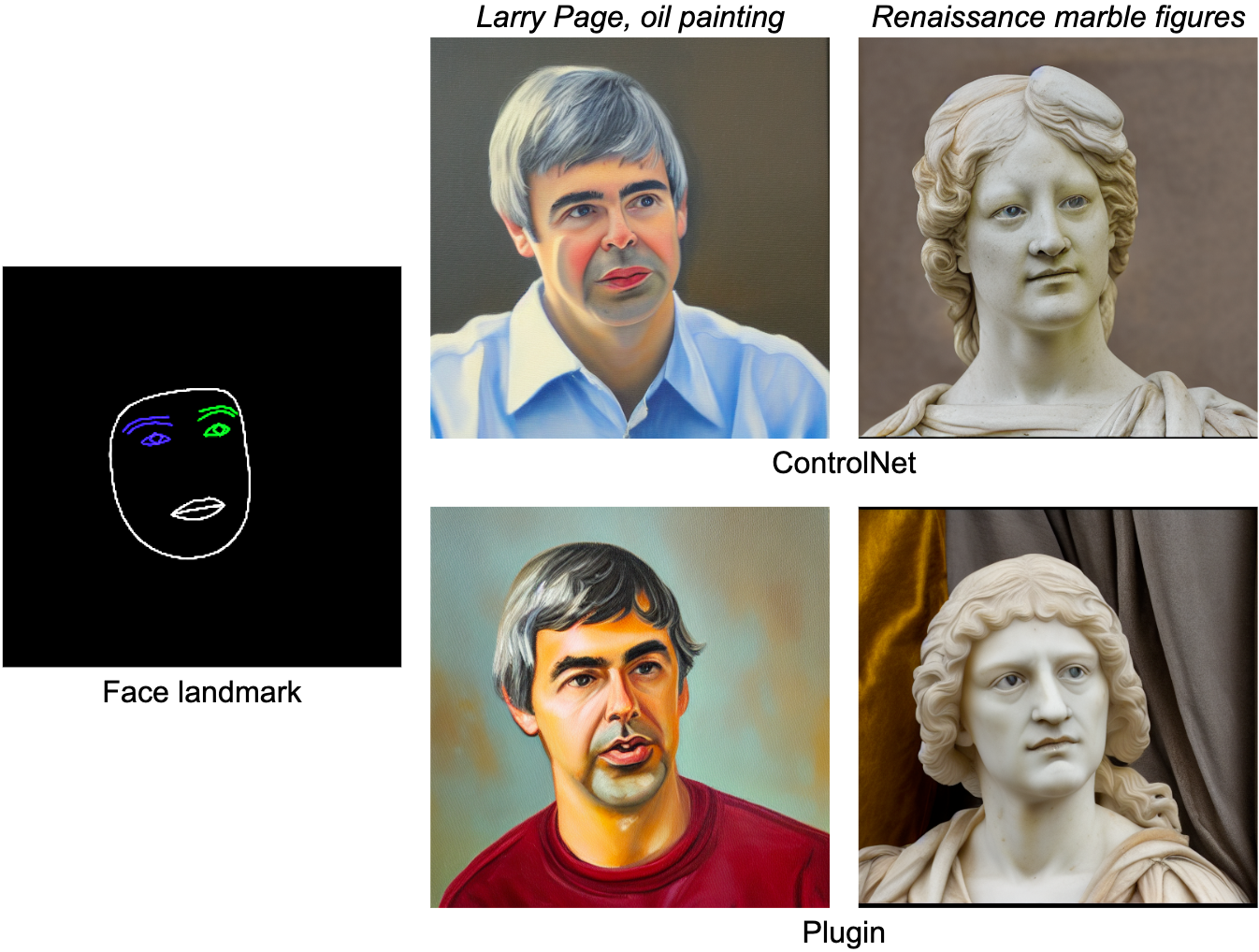 |
| Face-landmark plugin for text-to-image generation, in contrast with ControlNet. |
Holistic Landmark
MediaPipe Holistic Landmarker process consists of landmarks of physique pose, palms, and face mesh. Below, we generate numerous stylized photographs by conditioning on the holistic options.
 |
| Holistic-landmark plugin for text-to-image generation. |
Depth
 |
| Depth-plugin for text-to-image generation. |
Canny Edge
 |
| Canny-edge plugin for text-to-image generation. |
Evaluation
We conduct a quantitative research of the face landmark plugin to reveal the mannequin’s efficiency. The analysis dataset accommodates 5K human photographs. We examine the generation high quality as measured by the extensively used metrics, Fréchet Inception Distance (FID) and CLIP scores. The base mannequin is a pre-trained text-to-image diffusion mannequin. We use Stable Diffusion v1.5 right here.
As proven within the following desk, each ControlNet and the MediaPipe diffusion plugin produce a lot better pattern high quality than the bottom mannequin, when it comes to FID and CLIP scores. Unlike ControlNet, which must run at each diffusion step, the MediaPipe plugin solely runs as soon as for every picture generated. We measured the efficiency of the three fashions on a server machine (with Nvidia V100 GPU) and a cell phone (Galaxy S23). On the server, we run all three fashions with 50 diffusion steps, and on cell, we run 20 diffusion steps utilizing the MediaPipe picture generation app. Compared with ControlNet, the MediaPipe plugin reveals a transparent benefit in inference effectivity whereas preserving the pattern high quality.
| Model | FID↓ | CLIP↑ | Inference Time (s) | |||||
| Nvidia V100 | Galaxy S23 | |||||||
| Base | 10.32 | 0.26 | 5.0 | 11.5 | ||||
| Base + ControlNet | 6.51 | 0.31 | 7.4 (+48%) | 18.2 (+58.3%) | ||||
| Base + MediaPipe Plugin | 6.50 | 0.30 | 5.0 (+0.2%) | 11.8 (+2.6%) | ||||
| Quantitative comparability on FID, CLIP, and inference time. |
We check the efficiency of the plugin on a variety of cell units from mid-tier to high-end. We checklist the outcomes on some consultant units within the following desk, protecting each Android and iOS.
| Device | Android | iOS | ||||||||||
| Pixel 4 | Pixel 6 | Pixel 7 | Galaxy S23 | iPhone 12 Pro | iPhone 13 Pro | |||||||
| Time (ms) | 128 | 68 | 50 | 48 | 73 | 63 | ||||||
| Inference time (ms) of the plugin on totally different cell units. |
Conclusion
In this work, we current MediaPipe, a transportable plugin for conditioned text-to-image generation. It injects options extracted from a situation picture to a diffusion mannequin, and consequently controls the picture generation. Portable plugins might be linked to pre-trained diffusion fashions working on servers or units. By working text-to-image generation and plugins absolutely on-device, we allow extra versatile functions of generative AI.
Acknowledgments
We’d wish to thank all crew members who contributed to this work: Raman Sarokin and Juhyun Lee for the GPU inference resolution; Khanh LeViet, Chuo-Ling Chang, Andrei Kulik, and Matthias Grundmann for management. Special due to Jiuqiang Tang, Joe Zou and Lu wang, who made this know-how and all of the demos working on-device.