

Have you ever puzzled how complicated phenomena like fluid flows, warmth switch, and even the formation of patterns in nature might be described mathematically? The reply lies in partial differential equations (PDEs), that are highly effective instruments used to mannequin and perceive intricate spatio-temporal processes throughout varied scientific domains. However, fixing these equations analytically is usually a daunting activity, typically requiring computational strategies or simulations. This is the place machine studying comes into play, providing a novel method to deal with PDE issues by studying to approximate the options instantly from information.
Traditionally, fixing PDEs concerned numerical strategies that may very well be computationally costly, particularly for complicated programs or high-dimensional issues. Recently, researchers have been exploring utilizing neural networks to be taught the mappings between enter situations and output options of PDEs. However, most present approaches are restricted to particular equations or battle to generalize to unseen programs with out fine-tuning.
In a outstanding step ahead, a workforce of researchers has developed PROSE-PDE (Figure 3), a multimodal neural community mannequin designed to be a basis for fixing a variety of time-dependent PDEs, together with nonlinear diffusive, dispersive, conservation legal guidelines, and wave equations. The key innovation lies in PROSE-PDE’s capacity to be taught a number of operators concurrently and extrapolate bodily phenomena throughout totally different governing programs. But how does it work?
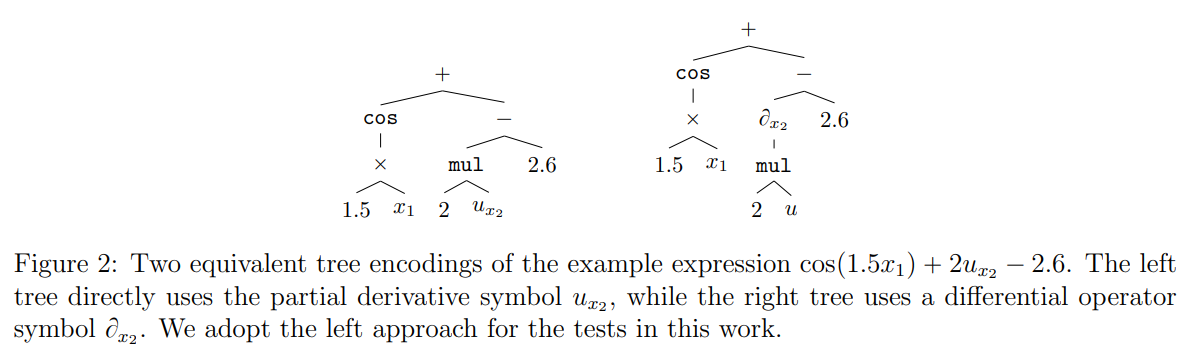
At the core of PROSE-PDE is a novel method referred to as Multi-Operator Learning (MOL). Unlike conventional approaches that be taught a single operator for a selected PDE, MOL trains a unified mannequin to approximate a number of operators concurrently. This is achieved by symbolic encoding (proven in Figure 2), the place equations are represented as trainable tokens in a Polish notation format. The mannequin can then be taught to affiliate these symbolic representations with the corresponding information options.
The PROSE-PDE structure includes 5 most important parts: Data Encoder, Symbol Encoder, Feature Fusion, Data Decoder, and Symbol Decoder. The Data Encoder processes the enter information sequence, whereas the Symbol Encoder handles the symbolic equation guesses. These encoded options are then fused collectively, permitting data change between the info and symbolic representations. The Data Decoder synthesizes the fused options to foretell the output options, and the Symbol Decoder refines and generates the corresponding symbolic expressions.
However, what units PROSE-PDE aside is its capacity to extrapolate bodily options throughout totally different programs. Through intensive experiments, the researchers demonstrated that PROSE-PDE might generalize to unseen mannequin parameters, predict variables at future time factors, and even deal with totally new bodily programs not encountered throughout coaching. This outstanding functionality is attributed to the mannequin’s capacity to summary and switch underlying bodily legal guidelines from the coaching information.
The analysis outcomes are promising, with PROSE-PDE attaining low relative prediction errors (< 3.1%) and excessive R^2 scores on a various set of 20 PDEs. Moreover, the mannequin efficiently recovered unknown equations with an error of solely 0.549%. These findings pave the way in which for a general-purpose basis mannequin for scientific purposes able to effectively fixing complicated PDE issues and extrapolating bodily insights throughout totally different programs.
While the present work focuses on one-dimensional time-dependent PDEs, the researchers envision extending PROSE-PDE to multi-dimensional and non-time-dependent equations. As information turns into more and more plentiful in scientific domains, the potential for such basis fashions to revolutionize our understanding and modeling of complicated bodily phenomena is really thrilling.
Check out the Paper. All credit score for this analysis goes to the researchers of this venture. Also, don’t neglect to observe us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our publication..
Don’t Forget to affix our 40k+ ML SubReddit
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is at present pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning fanatic. He is captivated with analysis and the newest developments in Deep Learning, Computer Vision, and associated fields.