

Time-series forecasting is a crucial analysis space that’s essential to a number of scientific and industrial purposes, like retail provide chain optimization, power and site visitors prediction, and climate forecasting. In retail use circumstances, for instance, it has been noticed that bettering demand forecasting accuracy can meaningfully scale back stock prices and improve income.
Modern time-series purposes can contain forecasting lots of of hundreds of correlated time-series (e.g., calls for of various merchandise for a retailer) over lengthy horizons (e.g., 1 / 4 or yr away at day by day granularity). As such, time-series forecasting fashions must fulfill the next key criterias:
- Ability to deal with auxiliary options or covariates: Most use-cases can profit tremendously from successfully utilizing covariates, as an illustration, in retail forecasting, holidays and product particular attributes or promotions can have an effect on demand.
- Suitable for various information modalities: It ought to be capable of deal with sparse depend information, e.g., intermittent demand for a product with low quantity of gross sales whereas additionally with the ability to mannequin strong steady seasonal patterns in site visitors forecasting.
A lot of neural community–based mostly options have been capable of present good efficiency on benchmarks and in addition assist the above criterion. However, these strategies are sometimes sluggish to coach and might be costly for inference, particularly for longer horizons.
In “Long-term Forecasting with TiDE: Time-series Dense Encoder”, we current an all multilayer perceptron (MLP) encoder-decoder structure for time-series forecasting that achieves superior efficiency on lengthy horizon time-series forecasting benchmarks when in comparison with transformer-based options, whereas being 5–10x quicker. Then in “On the benefits of maximum likelihood estimation for Regression and Forecasting”, we show that utilizing a rigorously designed coaching loss operate based mostly on most chance estimation (MLE) might be efficient in dealing with totally different information modalities. These two works are complementary and might be utilized as part of the identical mannequin. In truth, they are going to be obtainable quickly in Google Cloud AI’s Vertex AutoML Forecasting.
TiDE: A easy MLP structure for quick and correct forecasting
Deep studying has proven promise in time-series forecasting, outperforming conventional statistical strategies, particularly for big multivariate datasets. After the success of transformers in pure language processing (NLP), there have been a number of works evaluating variants of the Transformer structure for lengthy horizon (the period of time into the longer term) forecasting, reminiscent of FEDformer and PatchTST. However, different work has urged that even linear fashions can outperform these transformer variants on time-series benchmarks. Nonetheless, easy linear fashions will not be expressive sufficient to deal with auxiliary options (e.g., vacation options and promotions for retail demand forecasting) and non-linear dependencies on the previous.
We current a scalable MLP-based encoder-decoder mannequin for quick and correct multi-step forecasting. Our mannequin encodes the previous of a time-series and all obtainable options utilizing an MLP encoder. Subsequently, the encoding is mixed with future options utilizing an MLP decoder to yield future predictions. The structure is illustrated beneath.
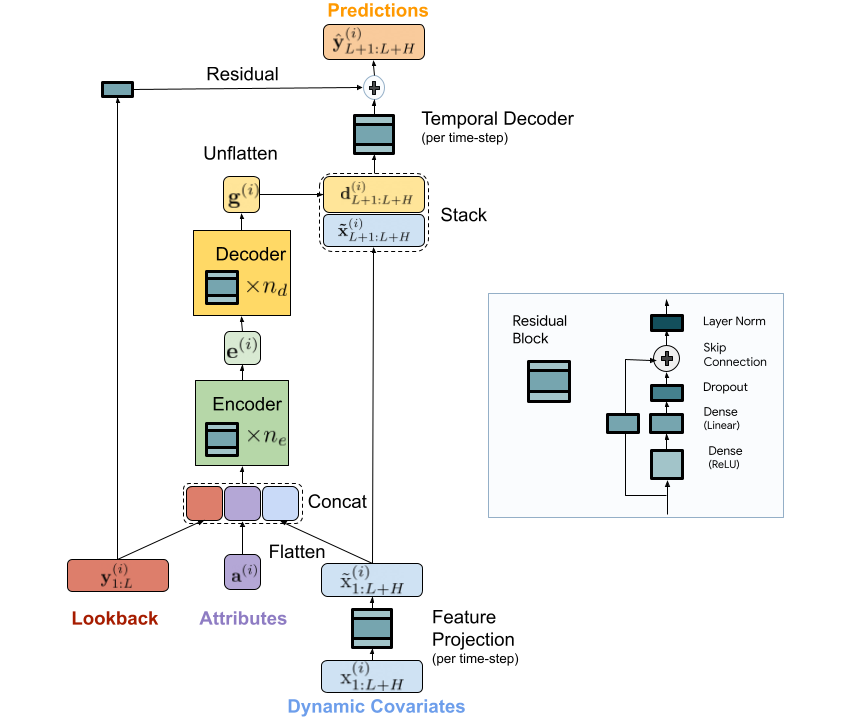 |
| TiDE mannequin structure for multi-step forecasting. |
TiDE is greater than 10x quicker in coaching in comparison with transformer-based baselines whereas being extra correct on benchmarks. Similar beneficial properties might be noticed in inference because it solely scales linearly with the size of the context (the variety of time-steps the mannequin appears to be like again) and the prediction horizon. Below on the left, we present that our mannequin might be 10.6% higher than the very best transformer-based baseline (PatchTST) on a well-liked site visitors forecasting benchmark, in phrases of check imply squared error (MSE). On the precise, we present that on the identical time our mannequin can have a lot quicker inference latency than PatchTST.
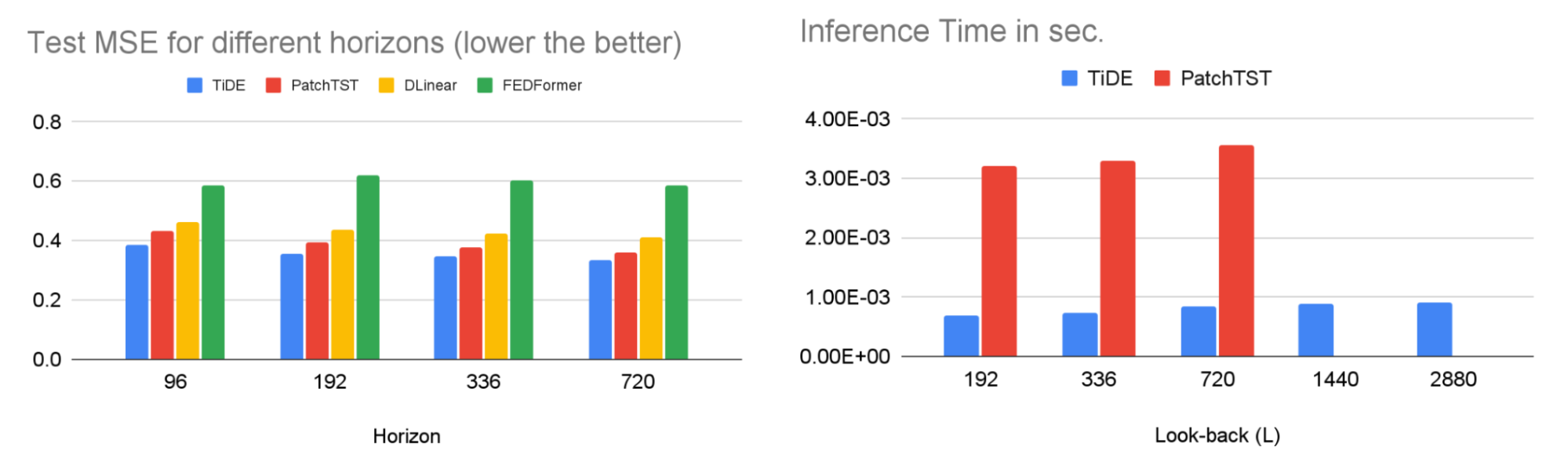 |
| Left: MSE on the check set of a well-liked site visitors forecasting benchmark. Right: inference time of TiDE and PatchTST as a operate of the look-back size. |
Our analysis demonstrates that we will make the most of MLP’s linear computational scaling with look-back and horizon sizes with out sacrificing accuracy, whereas transformers scale quadratically in this case.
Probabilistic loss capabilities
In most forecasting purposes the top person is in common goal metrics just like the imply absolute share error (MAPE), weighted absolute share error (WAPE), and many others. In such eventualities, the usual method is to make use of the identical goal metric because the loss operate whereas coaching. In “On the benefits of maximum likelihood estimation for Regression and Forecasting”, accepted at ICLR, we present that this method won’t at all times be the very best. Instead, we advocate utilizing the utmost chance loss for a rigorously chosen household of distributions (mentioned extra beneath) that may seize inductive biases of the dataset throughout coaching. In different phrases, as an alternative of straight outputting level predictions that decrease the goal metric, the forecasting neural community predicts the parameters of a distribution in the chosen household that greatest explains the goal information. At inference time, we will predict the statistic from the discovered predictive distribution that minimizes the goal metric of curiosity (e.g., the imply minimizes the MSE goal metric whereas the median minimizes the WAPE). Further, we will additionally simply receive uncertainty estimates of our forecasts, i.e., we will present quantile forecasts by estimating the quantiles of the predictive distribution. In a number of use circumstances, correct quantiles are important, as an illustration, in demand forecasting a retailer may wish to inventory for the ninetieth percentile to protect towards worst-case eventualities and keep away from misplaced income.
The alternative of the distribution household is essential in such circumstances. For instance, in the context of sparse depend information, we’d wish to have a distribution household that may put extra likelihood on zero, which is often generally known as zero-inflation. We suggest a combination of various distributions with discovered combination weights that may adapt to totally different information modalities. In the paper, we present that utilizing a combination of zero and a number of unfavourable binomial distributions works nicely in quite a lot of settings as it will possibly adapt to sparsity, a number of modalities, depend information, and information with sub-exponential tails.
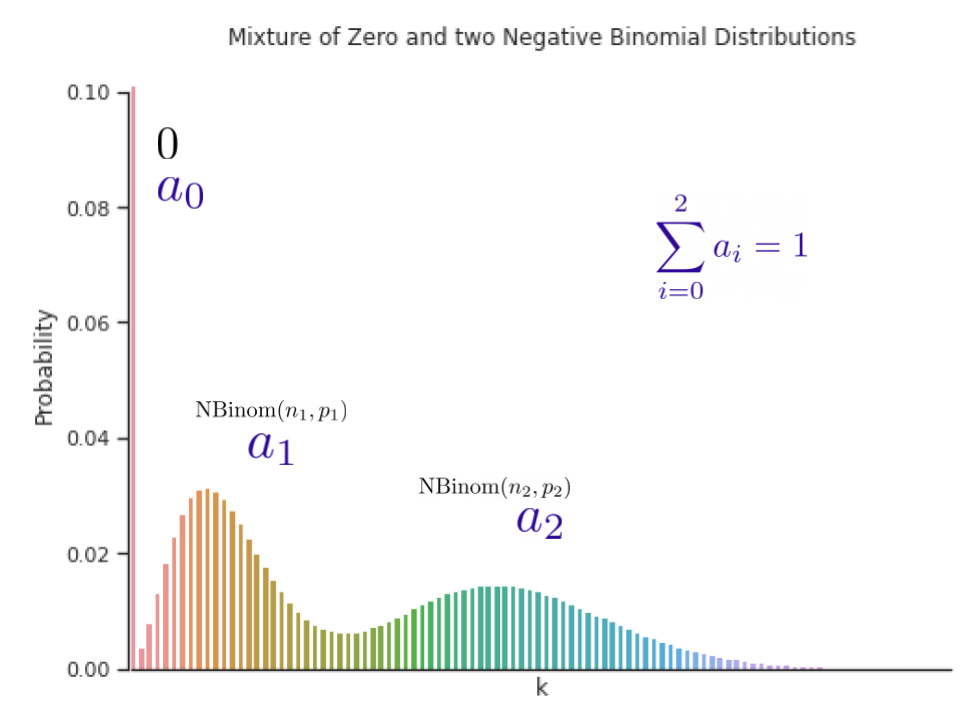 |
| A combination of zero and two unfavourable binomial distributions. The weights of the three elements, a1, a2 and a3, might be discovered throughout coaching. |
We use this loss operate for coaching Vertex AutoML fashions on the M5 forecasting competitors dataset and present that this easy change can result in a 6% achieve and outperform different benchmarks in the competitors metric, weighted root imply squared scaled error (WRMSSE).
| M5 Forecasting | WRMSSE |
| Vertex AutoML | 0.639 +/- 0.007 |
| Vertex AutoML with probabilistic loss | 0.581 +/- 0.007 |
| DeepAR | 0.789 +/- 0.025 |
| FEDFormer | 0.804 +/- 0.033 |
Conclusion
We have proven how TiDE, along with probabilistic loss capabilities, permits quick and correct forecasting that routinely adapts to totally different information distributions and modalities and in addition gives uncertainty estimates for its predictions. It gives state-of-the-art accuracy amongst neural community–based mostly options at a fraction of the price of earlier transformer-based forecasting architectures, for large-scale enterprise forecasting purposes. We hope this work will even spur curiosity in revisiting (each theoretically and empirically) MLP-based deep time-series forecasting fashions.
Acknowledgements
This work is the results of a collaboration between a number of people throughout Google Research and Google Cloud, together with (in alphabetical order): Pranjal Awasthi, Dawei Jia, Weihao Kong, Andrew Leach, Shaan Mathur, Petros Mol, Shuxin Nie, Ananda Theertha Suresh, and Rose Yu.