

AI always evolves and wants environment friendly strategies to combine new information into current fashions. Rapid data technology means fashions can shortly develop into outdated, which has given beginning to mannequin enhancing. In this complicated area, the objective is to imbue AI fashions with the newest data with out undermining their foundational construction or general efficiency.
The problem is twofold: on the one hand, precision is required in integrating new info to make sure the mannequin’s relevance, and on the different, the course of have to be environment friendly to maintain tempo with the steady inflow of data. Historically, methods similar to ROME and MEMIT have supplied options, every with distinct benefits. ROME, for example, is adept at making correct, singular modifications, whereas MEMIT extends these capabilities to batched updates, enhancing the mannequin’s enhancing effectivity considerably.
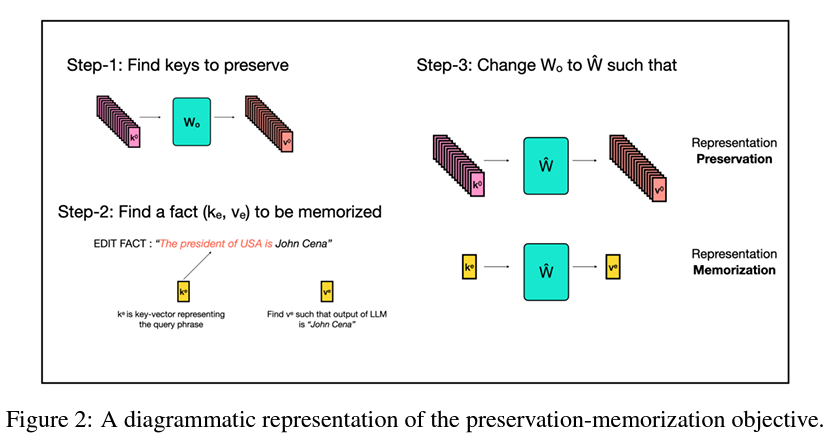
Enter EMMET, a groundbreaking algorithm devised by researchers from UC Berkeley, which synthesizes the strengths of each ROME and MEMIT inside a cohesive framework. This revolutionary strategy balances the meticulous preservation of a mannequin’s current traits with the seamless incorporation of recent knowledge. EMMET distinguishes itself by enabling batch edits, a feat achieved by rigorously managing the commerce-off between preserving the mannequin’s unique options and memorizing new info. This twin focus is pivotal for upholding the mannequin’s integrity whereas increasing its utility with present data.
The empirical analysis of EMMET reveals its adeptness in managing batch edits successfully as much as a batch measurement of 256, demonstrating a notable development in the area of mannequin enhancing. This functionality underscores the algorithm’s potential to reinforce the adaptability of AI programs, permitting them to evolve alongside the rising physique of information. However, as the scale of edits will increase, EMMET encounters challenges, highlighting the delicate equilibrium between theoretical targets and their sensible execution.
This exploration into EMMET and its predecessors, ROME and MEMIT, gives priceless insights into the ongoing improvement of mannequin enhancing methods. It emphasizes the important position of innovation in guaranteeing that AI programs stay related and correct, able to adapting to the fast modifications attribute of the digital period. The journey from singular edits to the batch enhancing capabilities of EMMET marks a major milestone in the pursuit of extra dynamic and adaptable AI fashions.
Furthermore, the efficiency metrics related to EMMET, as revealed in empirical assessments, showcase its efficacy and effectivity in mannequin enhancing. For occasion, on fashions like GPT2-XL and GPT-J, EMMET demonstrated distinctive enhancing efficiency, with efficacy scores reaching 100% in some instances. This efficiency is indicative of EMMET’s robustness and its potential to affect the panorama of AI mannequin enhancing considerably.
The contributions of the UC Berkeley analysis staff in growing EMMET usually are not only a technical achievement; they characterize a pivotal step in direction of realizing the full potential of AI programs. By enabling these programs to remain present with the newest information with out sacrificing their core performance, EMMET paves the means for extra resilient and versatile AI purposes. This evolution of mannequin enhancing methods from ROME and MEMIT to EMMET encapsulates the ongoing endeavor to harmonize the accuracy and effectivity of AI fashions with the dynamic nature of data in the digital age.
In conclusion, the introduction of EMMET heralds a brand new period in mannequin enhancing, the place the stability between preserving current mannequin options and incorporating new data is achieved with unprecedented precision and effectivity. This breakthrough enriches the area of synthetic intelligence and ensures that AI programs can proceed to evolve, reflecting the newest developments and information. The journey of innovation in mannequin enhancing, epitomized by EMMET, underscores the relentless pursuit of adapting AI programs to fulfill the calls for of a quickly altering world.
Check out the Paper. All credit score for this analysis goes to the researchers of this undertaking. Also, don’t overlook to comply with us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our publication..
Don’t Forget to affix our 39k+ ML SubReddit
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a deal with Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends superior technical information with sensible purposes. His present endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.