

The emergence of Large Language Models (LLMs) has remodeled the panorama of pure language processing (NLP). The introduction of the transformer structure marked a pivotal second, ushering in a brand new period in NLP. While a common definition for LLMs is missing, they’re typically understood as versatile machine studying fashions adept at concurrently dealing with varied pure language processing duties, showcasing these fashions’ fast evolution and impression on the area.
Four important duties in LLMs are pure language understanding, pure language era, knowledge-intensive duties, and reasoning means. The evolving panorama consists of numerous architectural methods, comparable to fashions using each encoders and decoders, encoder-only fashions like BERT, and decoder-only fashions like GPT-4. GPT-4’s decoder-only strategy excels in pure language era duties. Despite the enhanced efficiency of GPT-4 Turbo, its 1.7 trillion parameters elevate issues about substantial power consumption, emphasizing the want for sustainable AI options.
The researchers from McGill University have proposed the Pythia 70M mannequin, a pioneering strategy to enhancing the effectivity of LLM pre-training by advocating information distillation for cross-architecture switch. Drawing inspiration from the environment friendly Hyena mechanism, the methodology replaces consideration heads in transformer fashions with Hyena, offering a cheap various to standard pre-training. This strategy successfully tackles the intrinsic problem posed by processing lengthy contextual data in quadratic consideration mechanisms, providing a promising avenue for extra environment friendly and scalable LLMs.
The researchers make the most of the environment friendly Hyena mechanism, changing consideration heads in transformer fashions with Hyena. This modern strategy improves inference velocity and outperforms conventional pre-training in accuracy and effectivity. The methodology particularly addresses the problem of processing lengthy contextual data inherent in quadratic consideration mechanisms, striving to steadiness computational energy and environmental impression, showcasing a cheap and environmentally aware various to standard pre-training strategies.
Studies current perplexity scores for completely different fashions, together with Pythia-70M, pre-trained Hyena mannequin, Hyena pupil mannequin distilled with MSE loss, and Hyena pupil mannequin fine-tuned after distillation. The pre-trained Hyena mannequin reveals improved perplexity in comparison with Pythia-70M. Distillation additional enhances efficiency, with the lowest perplexity achieved by the Hyena pupil mannequin by way of fine-tuning. In language analysis duties utilizing the Language Model Evaluation Harness, the Hyena-based fashions show aggressive efficiency throughout varied pure language duties in comparison with the attention-based Pythia-70M trainer mannequin.
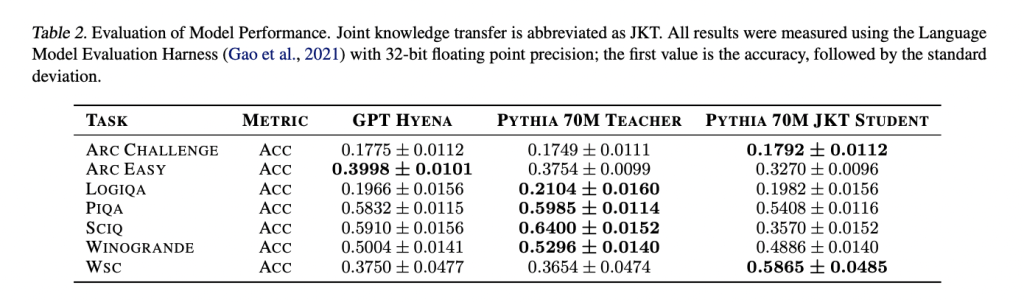
To conclude, the researchers from McGill University have proposed the Pythia 70M mannequin. Employing joint information switch with Hyena operators instead for consideration enhances the computational effectivity of LLMs throughout coaching. Evaluating perplexity scores on OpenWebText and WikiText datasets, the Pythia 70M Hyena mannequin, present process progressive information switch, outperforms its pre-trained counterpart. Fine-tuning post-knowledge switch additional reduces perplexity, indicating improved mannequin efficiency. Although the pupil Hyena mannequin reveals barely decrease accuracy in pure language duties in comparison with the trainer mannequin, the outcomes recommend that joint information switch with Hyena provides a promising various for coaching extra computationally environment friendly LLMs.
Check out the Paper. All credit score for this analysis goes to the researchers of this challenge. Also, don’t neglect to comply with us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our publication..
Don’t Forget to hitch our Telegram Channel
![]()
Asjad is an intern marketing consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.