

Mixture-of-experts (MoE) fashions have revolutionized synthetic intelligence by enabling the dynamic allocation of duties to specialised elements inside bigger fashions. However, a serious problem in adopting MoE fashions is their deployment in environments with restricted computational sources. The huge measurement of these fashions typically surpasses the reminiscence capabilities of normal GPUs, limiting their use in low-resource settings. This limitation hampers the fashions’ effectiveness and challenges researchers and builders aiming to leverage MoE fashions for advanced computational duties with out entry to high-end {hardware}.
Existing strategies for deploying MoE fashions in constrained environments usually contain offloading half of the mannequin computation to the CPU. While this method helps handle GPU reminiscence limitations, it introduces vital latency as a consequence of the gradual information transfers between the CPU and GPU. State-of-the-art MoE fashions additionally typically make use of various activation features, equivalent to SiLU, which makes it difficult to use sparsity-exploiting methods immediately. Pruning channels not shut sufficient to zero may negatively affect the mannequin’s efficiency, requiring a extra refined method to leverage sparsity.
A workforce of researchers from the University of Washington has launched Fiddler, an progressive answer designed to optimize the deployment of MoE fashions by effectively orchestrating CPU and GPU sources. Fiddler minimizes the information switch overhead by executing knowledgeable layers on the CPU, lowering the latency related with shifting information between CPU and GPU. This method addresses the limitations of current strategies and enhances the feasibility of deploying giant MoE fashions in resource-constrained environments.
Fiddler distinguishes itself by leveraging the computational capabilities of the CPU for knowledgeable layer processing whereas minimizing the quantity of information transferred between the CPU and GPU. This methodology drastically cuts down the latency for CPU-GPU communication, enabling the system to run giant MoE fashions, equivalent to the Mixtral-8x7B with over 90GB of parameters, effectively on a single GPU with restricted reminiscence. Fiddler’s design showcases a big technical innovation in AI mannequin deployment.
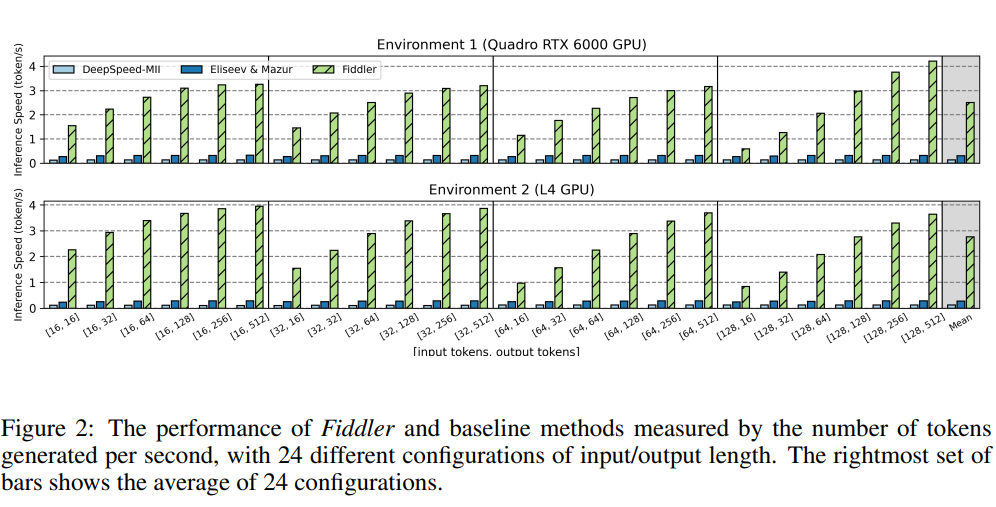
Fiddler’s effectiveness is underscored by its efficiency metrics, which exhibit an order of magnitude enchancment over conventional offloading strategies. The efficiency is measured by the quantity of tokens generated per second. Fiddler efficiently ran the uncompressed Mixtral-8x7B mannequin in exams, rendering over three tokens per second on a single 24GB GPU. It improves with longer output lengths for the identical enter size, as the latency of the prefill stage is amortized. On common, Fiddler is quicker than Eliseev Mazur by 8.2 instances to 10.1 instances and faster than DeepSpeed-MII by 19.4 instances to 22.5 instances, relying on the surroundings.
In conclusion, Fiddler represents a big leap ahead in enabling the environment friendly inference of MoE fashions in environments with restricted computational sources. By ingeniously using CPU and GPU for mannequin inference, Fiddler overcomes the prevalent challenges confronted by conventional deployment strategies, providing a scalable answer that enhances the accessibility of superior MoE fashions. This breakthrough can probably democratize large-scale AI fashions, paving the approach for broader purposes and analysis in synthetic intelligence.
Check out the Paper and Github. All credit score for this analysis goes to the researchers of this undertaking. Also, don’t overlook to observe us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our publication..
Don’t Forget to hitch our Telegram Channel
You can also like our FREE AI Courses….
![]()
Nikhil is an intern advisor at Marktechpost. He is pursuing an built-in twin diploma in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Material Science, he’s exploring new developments and creating alternatives to contribute.