
 for Efficient and Rapid Deployment in Large Language Models")
A major problem in deploying massive language fashions (LLMs) and latent variable fashions (LVMs) is balancing low inference overhead with the power to quickly swap adapters. Traditional strategies similar to Low Rank Adaptation (LoRA) both fuse adapter parameters into the bottom mannequin weights, shedding speedy switching functionality, or keep adapter parameters individually, incurring vital latency. Additionally, current strategies wrestle with idea loss when a number of adapters are used concurrently. Addressing these points is crucial for deploying AI fashions in resource-constrained environments like cellular units and guaranteeing strong efficiency throughout various functions.
LoRA and its variants are the first strategies used to adapt massive generative fashions. LoRA is favored for its effectivity throughout coaching and inference, but it surely modifies a good portion of the bottom mannequin’s weights when fused, resulting in massive reminiscence and latency prices throughout speedy switching. In unfused mode, LoRA incurs as much as 30% greater inference latency. Furthermore, LoRA suffers from idea loss in multi-adapter settings, the place completely different adapters overwrite one another’s affect, degrading the mannequin’s efficiency. Sparse adaptation strategies have been explored, however they typically require advanced implementations and don’t absolutely tackle speedy switching and idea retention points.
Researchers from Qualcomm AI suggest Sparse High Rank Adapters (SHiRA), a extremely sparse adapter framework that modifies solely 1-2% of the bottom mannequin’s weights. This framework permits speedy switching by minimizing the variety of weights that must be up to date and mitigates idea loss by way of its sparse construction. The researchers leveraged gradient masking to replace solely essentially the most crucial weights throughout coaching, sustaining excessive efficiency with minimal parameter modifications. SHiRA’s design ensures that it stays light-weight and environment friendly, making it appropriate for deployment on cellular units and different resource-constrained environments.
The SHiRA framework is carried out utilizing a gradient masking approach the place a sparse masks determines which weights are trainable. Various methods to create these masks embrace random choice, weight magnitude, gradient magnitude, and SNIP (Sensitivity-based Pruning). The adapters may be quickly switched by storing solely the non-zero weights and their indices and making use of them utilizing environment friendly scatter operations throughout inference. The researchers additionally present a memory- and latency-efficient implementation based mostly on the Parameter-Efficient Fine-Tuning (PEFT) library, which reduces GPU reminiscence utilization by 16% in comparison with normal LoRA and trains at practically the identical pace.

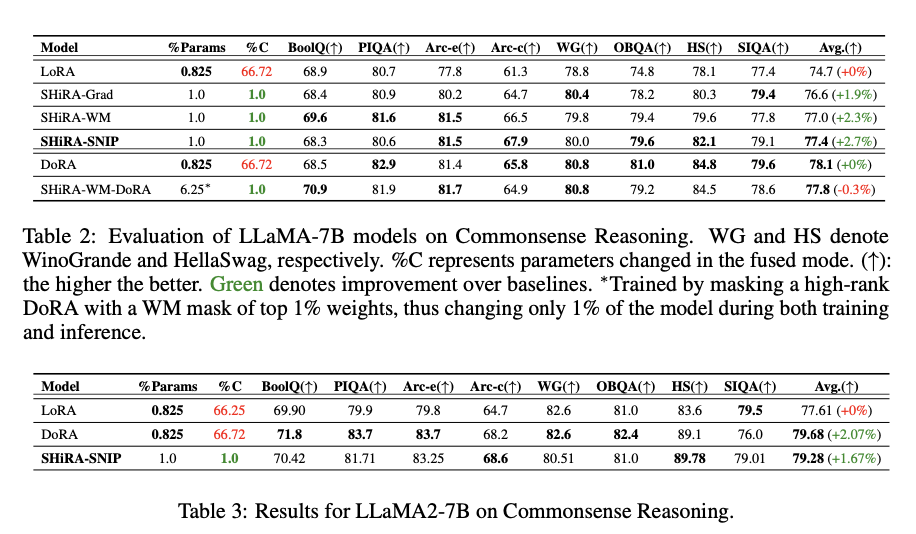
SHiRA demonstrates superior efficiency in intensive experiments on each LLMs and LVMs. The method persistently outperforms conventional LoRA strategies, attaining as much as 2.7% greater accuracy in commonsense reasoning duties. Additionally, SHiRA maintains excessive picture high quality in model switch duties, successfully addressing the idea loss points that plague LoRA. SHiRA achieves considerably greater HPSv2 scores on model switch datasets, indicating superior picture technology high quality. By modifying solely 1-2% of the bottom mannequin’s weights, SHiRA ensures speedy adapter switching and minimal inference overhead, making it extremely environment friendly and sensible for deployment in resource-constrained environments similar to cellular units.
In conclusion, Sparse High Rank Adapters (SHiRA) signify a big development in adapter strategies for AI fashions. SHiRA addresses crucial challenges of speedy adapter switching and idea loss in multi-adapter settings whereas sustaining low inference overhead. By modifying solely 1-2% of the bottom mannequin’s weights, this method affords a sensible and environment friendly resolution for deploying massive fashions in resource-constrained environments, thus advancing the sphere of AI analysis and deployment.
Check out the Paper. All credit score for this analysis goes to the researchers of this challenge. Also, don’t neglect to comply with us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you want our work, you’ll love our e-newsletter..
Don’t Forget to hitch our 45k+ ML SubReddit
🚀 Create, edit, and increase tabular information with the primary compound AI system, Gretel Navigator, now typically out there! [Advertisement]
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree on the Indian Institute of Technology, Kharagpur. He is captivated with information science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.