

The purpose of pure language processing (NLP) is to develop computational fashions that may perceive and generate pure language. By capturing the statistical patterns and constructions of text-based pure language, language fashions can predict and generate coherent and significant sequences of phrases. Enabled by the growing use of the extremely profitable Transformer mannequin structure and with coaching on giant quantities of textual content (with proportionate compute and mannequin dimension), giant language fashions (LLMs) have demonstrated exceptional success in NLP duties.
However, modeling spoken human language stays a difficult frontier. Spoken dialog methods have conventionally been constructed as a cascade of computerized speech recognition (ASR), pure language understanding (NLU), response technology, and text-to-speech (TTS) methods. However, up to now there have been few succesful end-to-end methods for the modeling of spoken language: i.e., single fashions that may take speech inputs and generate its continuation as speech outputs.
Today we current a new method for spoken language modeling, referred to as Spectron, revealed in “Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM.” Spectron is the primary spoken language mannequin that’s skilled end-to-end to immediately course of spectrograms as each enter and output, as an alternative of studying discrete speech representations. Using solely a pre-trained textual content language mannequin, it may be fine-tuned to generate high-quality, semantically correct spoken language. Furthermore, the proposed mannequin improves upon direct initialization in retaining the information of the unique LLM as demonstrated by way of spoken question answering datasets.
We present that a pre-trained speech encoder and a language mannequin decoder allow end-to-end coaching and state-of-the-art efficiency with out sacrificing representational constancy. Key to that is a novel end-to-end coaching goal that implicitly supervises speech recognition, textual content continuation, and conditional speech synthesis in a joint method. A brand new spectrogram regression loss additionally supervises the mannequin to match the higher-order derivatives of the spectrogram within the time and frequency area. These derivatives specific info aggregated from a number of frames without delay. Thus, they specific wealthy, longer-range details about the form of the sign. Our general scheme is summarized within the following determine:
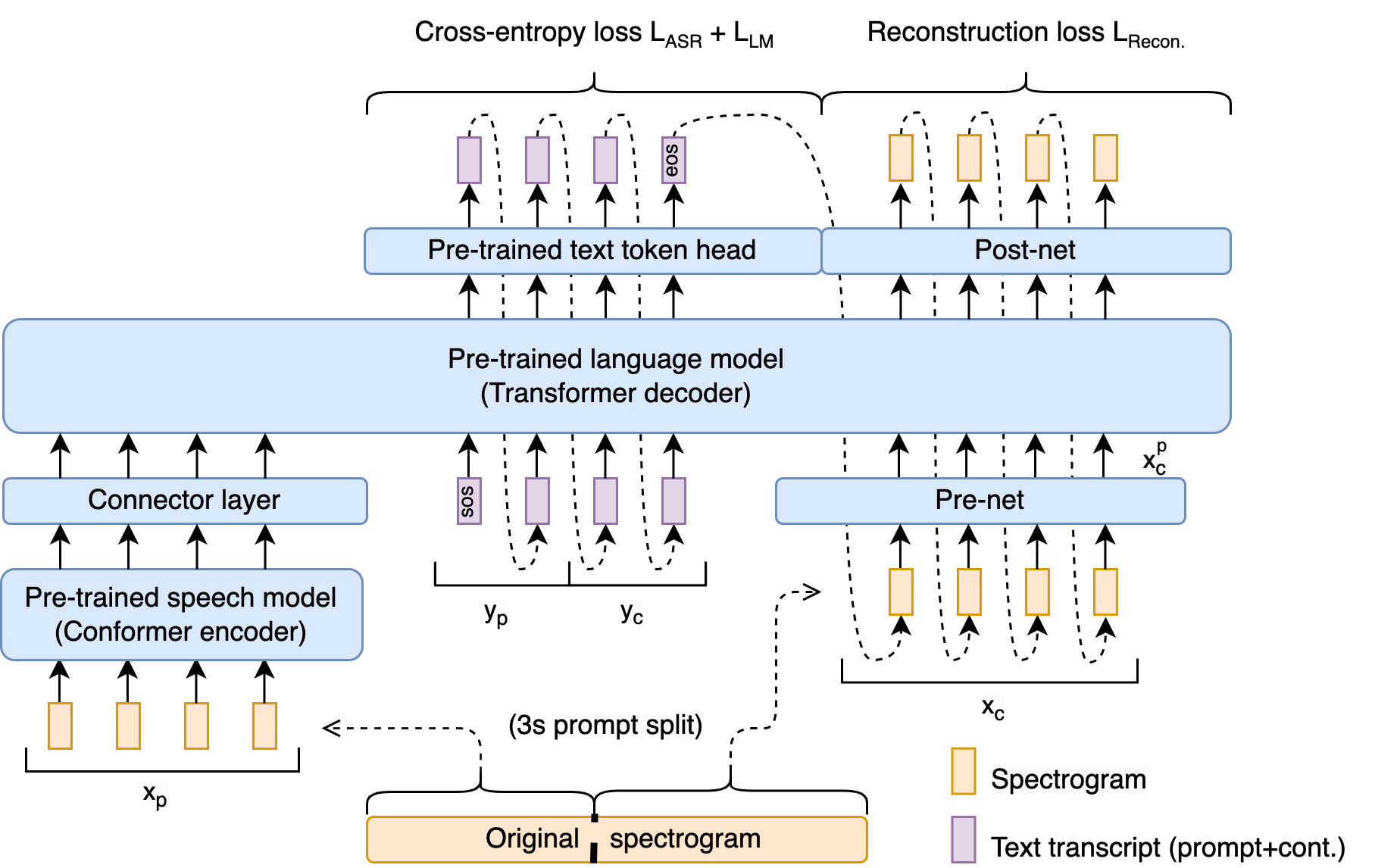 |
| The Spectron mannequin connects the encoder of a speech recognition mannequin with a pre-trained Transformer-based decoder language mannequin. At coaching, speech utterances cut up into a immediate and its continuation. Then the total transcript (immediate and continuation) is reconstructed together with the continuation’s speech options. At inference, solely a immediate is offered; the immediate’s transcription, textual content continuation, and speech continuations are all generated by the mannequin. |
Spectron structure
The structure is initialized with a pre-trained speech encoder and a pre-trained decoder language mannequin. The encoder is prompted with a speech utterance as enter, which it encodes into steady linguistic options. These options feed into the decoder as a prefix, and the entire encoder-decoder is optimized to collectively reduce a cross-entropy loss (for speech recognition and transcript continuation) and a novel reconstruction loss (for speech continuation). During inference, one supplies a spoken speech immediate, which is encoded and then decoded to offer each textual content and speech continuations.
Speech encoder
The speech encoder is a 600M-parameter conformer encoder pre-trained on large-scale information (12M hours). It takes the spectrogram of the supply speech as enter, producing a hidden illustration that includes each linguistic and acoustic info. The enter spectrogram is first subsampled using a convolutional layer and then processed by a collection of conformer blocks. Each conformer block consists of a feed-forward layer, a self-attention layer, a convolution layer, and a second feed-forward layer. The outputs are handed by way of a projection layer to match the hidden representations to the embedding dimension of the language mannequin.
Language mannequin
We use a 350M or 1B parameter decoder language mannequin (for the continuation and question-answering duties, respectively) skilled within the method of PaLM 2. The mannequin receives the encoded options of the immediate as a prefix. Note that that is the one connection between the speech encoder and the LM decoder; i.e., there is no such thing as a cross-attention between the encoder and the decoder. Unlike most spoken language fashions, throughout coaching, the decoder is teacher-forced to foretell the textual content transcription, textual content continuation, and speech embeddings. To convert the speech embeddings to and from spectrograms, we introduce light-weight modules pre- and post-network.
By having the identical structure decode the intermediate textual content and the spectrograms, we acquire two advantages. First, the pre-training of the LM within the textual content area permits continuation of the immediate within the textual content area earlier than synthesizing the speech. Secondly, the expected textual content serves as intermediate reasoning, enhancing the standard of the synthesized speech, analogous to enhancements in text-based language fashions when using intermediate scratchpads or chain-of-thought (CoT) reasoning.
Acoustic projection layers
To allow the language mannequin decoder to mannequin spectrogram frames, we make use of a multi-layer perceptron “pre-net” to challenge the bottom fact spectrogram speech continuations to the language mannequin dimension. This pre-net compresses the spectrogram enter into a decrease dimension, creating a bottleneck that aids the decoding course of. This bottleneck mechanism prevents the mannequin from repetitively producing the identical prediction within the decoding course of. To challenge the LM output from the language mannequin dimension to the spectrogram dimension, the mannequin employs a “post-net”, which can be a multi-layer perceptron. Both pre- and post-networks are two-layer multi-layer perceptrons.
Training goal
The coaching methodology of Spectron makes use of two distinct loss capabilities: (i) cross-entropy loss, employed for each speech recognition and transcript continuation, and (ii) regression loss, employed for speech continuation. During coaching, all parameters are up to date (speech encoder, projection layer, LM, pre-net, and post-net).
Audio samples
Following are examples of speech continuation and question answering from Spectron:
Speech Continuation |
|
| Prompt: | |
| Continuation: | |
| Prompt: | |
| Continuation: | |
| Prompt: | |
| Continuation: | |
| Prompt: | |
| Continuation: | |
Question Answering |
|
| Question: | |
| Answer: | |
| Question: | |
| Answer: | |
Performance
To empirically consider the efficiency of the proposed method, we performed experiments on the Libri-Light dataset. Libri-Light is a 60k hour English dataset consisting of unlabelled speech readings from LibriVox audiobooks. We utilized a frozen neural vocoder referred to as WaveFit to transform the expected spectrograms into uncooked audio. We experiment with two duties, speech continuation and spoken question answering (QA). Speech continuation high quality is examined on the LibriSpeech check set. Spoken QA is examined on the Spoken WebQuestions datasets and a new check set named LLama questions, which we created. For all experiments, we use a 3 second audio immediate as enter. We evaluate our methodology towards present spoken language fashions: AudioLM, GSLM, TWIST and SpeechGPT. For the speech continuation process, we use the 350M parameter model of LM and the 1B model for the spoken QA process.
For the speech continuation process, we consider our methodology using three metrics. The first is log-perplexity, which makes use of an LM to judge the cohesion and semantic high quality of the generated speech. The second is imply opinion rating (MOS), which measures how pure the speech sounds to human evaluators. The third, speaker similarity, makes use of a speaker encoder to measure how related the speaker within the output is to the speaker within the enter. Performance in all 3 metrics might be seen within the following graphs.
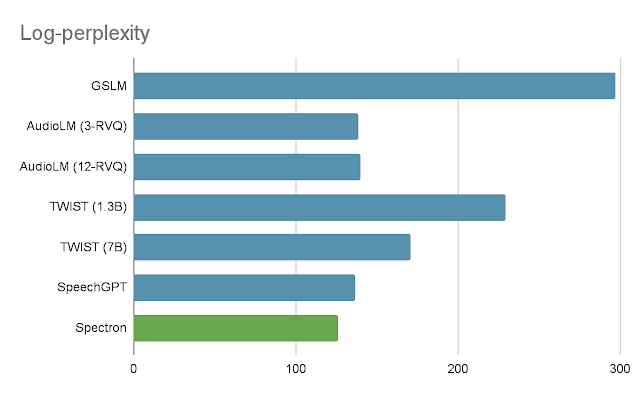 |
| Log-perplexity for completions of LibriSpeech utterances given a 3-second immediate. Lower is healthier. |
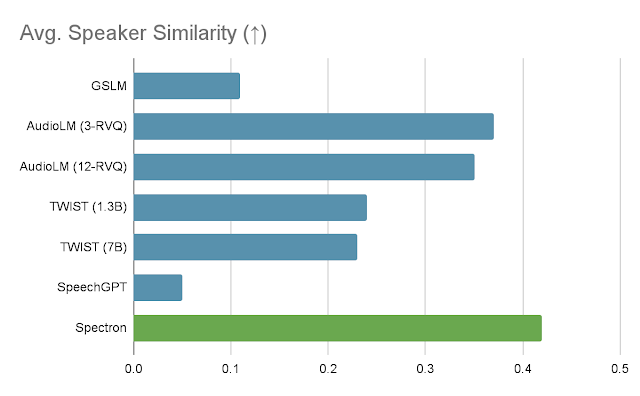 |
| Speaker similarity between the immediate speech and the generated speech using the speaker encoder. Higher is healthier. |
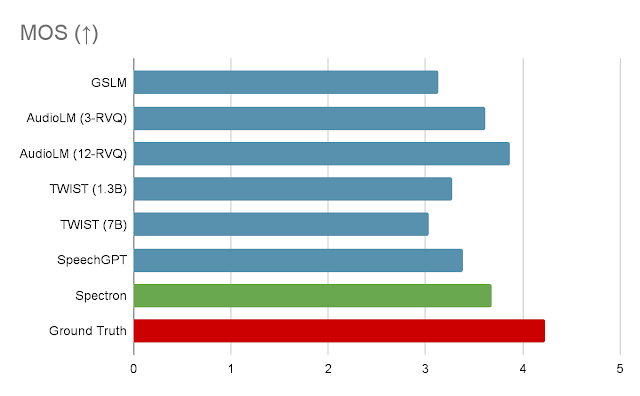 |
| MOS given by human customers on speech naturalness. Raters price 5-scale subjective imply opinion rating (MOS) ranging between 0 – 5 in naturalness given a speech utterance. Higher is healthier. |
As might be seen within the first graph, our methodology considerably outperforms GSLM and TWIST on the log-perplexity metric, and does barely higher than state-of-the-art strategies AudioLM and SpeechGPT. In phrases of MOS, Spectron exceeds the efficiency of all the opposite strategies apart from AudioLM. In phrases of speaker similarity, our methodology outperforms all different strategies.
To consider the flexibility of the fashions to carry out question answering, we use two spoken question answering datasets. The first is the LLama Questions dataset, which makes use of basic information questions in numerous domains generated using the LLama2 70B LLM. The second dataset is the WebQuestions dataset which is a basic question answering dataset. For analysis we use solely questions that match into the three second immediate size. To compute accuracy, solutions are transcribed and in comparison with the bottom fact solutions in textual content kind.
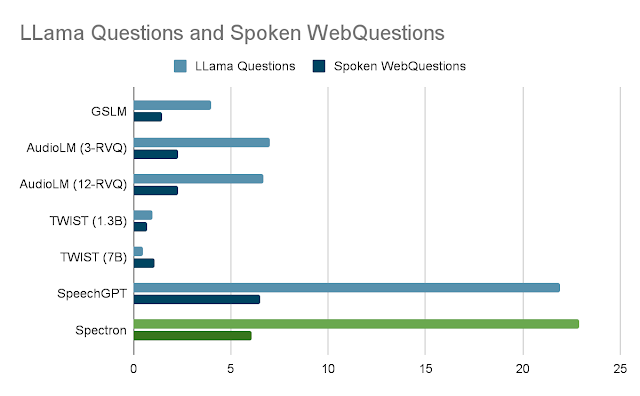 |
| Accuracy for Question Answering on the LLama Questions and Spoken WebQuestions datasets. Accuracy is computed using the ASR transcripts of spoken solutions. |
First, we observe that each one strategies have extra issue answering questions from the Spoken WebQuestions dataset than from the LLama questions dataset. Second, we observe that strategies centered round spoken language modeling equivalent to GSLM, AudioLM and TWIST have a completion-centric conduct moderately than direct question answering which hindered their skill to carry out QA. On the LLama questions dataset our methodology outperforms all different strategies, whereas SpeechGPT could be very shut in efficiency. On the Spoken WebQuestions dataset, our methodology outperforms all different strategies apart from SpeechGPT, which does marginally higher.
Acknowledgements
The direct contributors to this work embody Eliya Nachmani, Alon Levkovitch, Julian Salazar, Chulayutsh Asawaroengchai, Soroosh Mariooryad, RJ Skerry-Ryan and Michelle Tadmor Ramanovich. We additionally thank Heiga Zhen, Yifan Ding, Yu Zhang, Yuma Koizumi, Neil Zeghidour, Christian Frank, Marco Tagliasacchi, Nadav Bar, Benny Schlesinger and Blaise Aguera-Arcas.