
")
In language mannequin alignment, the effectiveness of reinforcement studying from human suggestions (RLHF) hinges on the excellence of the underlying reward mannequin. A pivotal concern is making certain the top quality of this reward mannequin, because it considerably influences the success of RLHF functions. The problem lies in creating a reward mannequin that precisely displays human preferences, a important consider attaining optimum efficiency and alignment in language fashions.
Recent developments in massive language fashions (LLMs) have been facilitated by aligning their conduct with human values. RLHF, a prevalent technique, guides fashions towards most well-liked outputs by defining a nuanced loss perform reflecting subjective textual content high quality. However, precisely modeling human preferences includes expensive information assortment. The high quality of choice fashions is dependent upon suggestions amount, response distribution, and label accuracy.
The researchers from ETH Zurich, Max Planck Institute for Intelligent Systems, Tubingen, and Google Research have launched West-of-N: Synthetic Preference Generation for Improved Reward Modeling, a novel methodology to improve reward mannequin high quality by incorporating artificial choice information into the coaching dataset. Building on the success of Best-of-N sampling methods in language mannequin coaching, they lengthen this strategy to reward mannequin coaching. The proposed self-training technique generates choice pairs by deciding on the finest and worst candidates from response swimming pools to particular queries.
The proposed West-of-N methodology generates artificial choice information by deciding on the finest and worst responses to a given question from the language mannequin’s coverage. Inspired by Best-of-N sampling methods, this self-training technique considerably enhances reward mannequin efficiency, comparable to the impression of incorporating an analogous amount of human choice information. The strategy is detailed in Algorithm 1, which features a theoretical assure of appropriate labeling for generated choice pairs. Filtering steps based mostly on mannequin confidence and response distribution additional improve the high quality of the generated information.

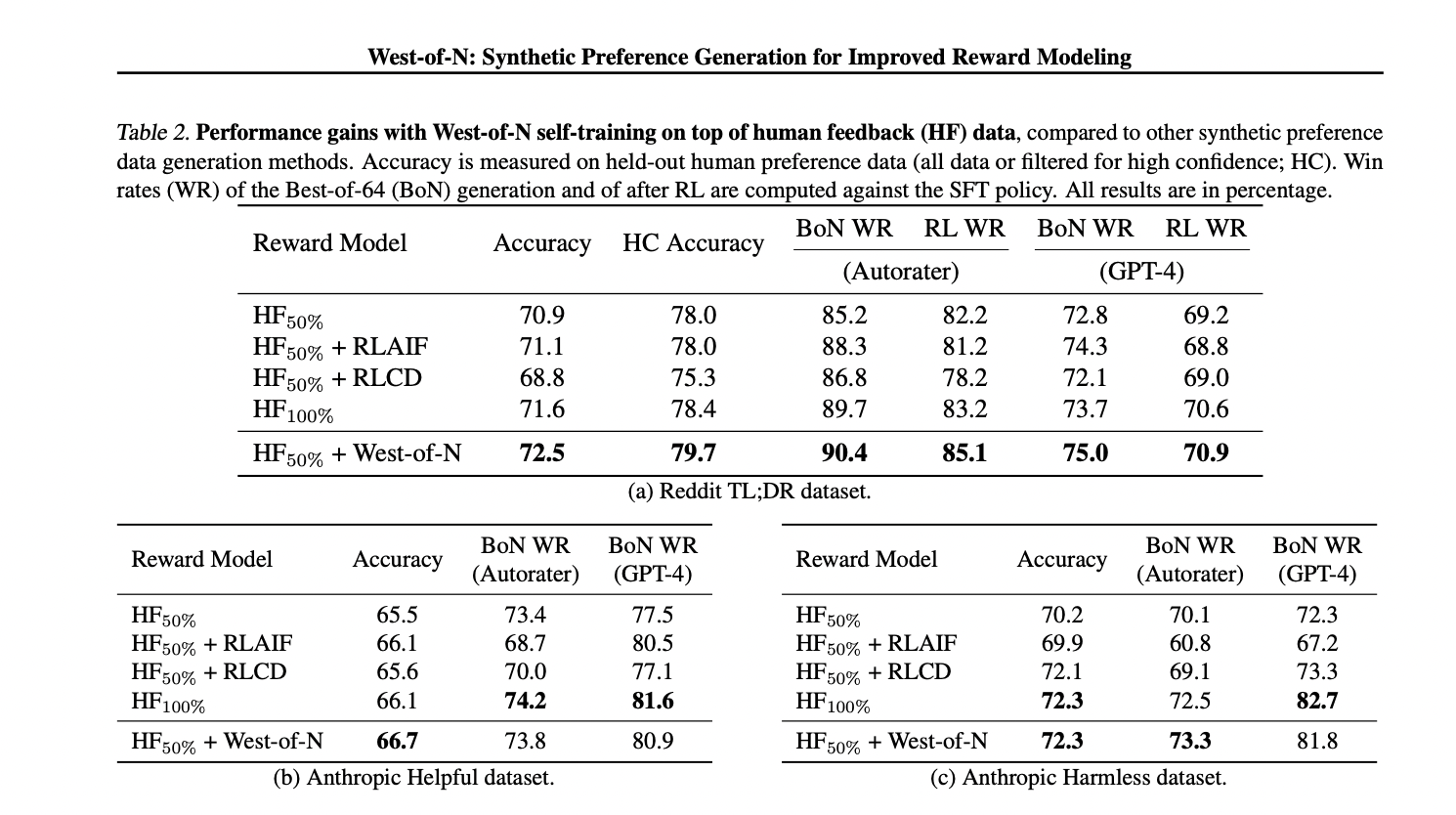
The examine evaluates the West-of-N artificial choice information era methodology on the Reddit TL;DR summarization and Anthropic Helpful and Harmless dialogue datasets. Results point out that West-of-N considerably enhances reward mannequin efficiency, surpassing beneficial properties from extra human suggestions information and outperforming different artificial choice era strategies corresponding to RLAIF and RLCD. West-of-N persistently improves mannequin accuracy, Best-of-N sampling, and RL-finetuning throughout completely different base choice varieties, demonstrating its effectiveness in language mannequin alignment.
To conclude, The researchers from Google Research and different establishments have proposed an efficient technique, West-of-N, to improve reward mannequin (RM) efficiency in RLHF. Experimental outcomes showcase the methodology’s efficacy throughout various preliminary choice information and datasets. The examine highlights the potential of Best-of-N sampling and semi-supervised studying for choice modeling. They additional instructed additional exploring strategies like noisy scholar coaching to elevate RM efficiency together with West-of-N.
Check out the Paper. All credit score for this analysis goes to the researchers of this challenge. Also, don’t overlook to comply with us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our publication..
Don’t Forget to be part of our Telegram Channel
![]()
Asjad is an intern marketing consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.