

Future fashions should obtain superior suggestions for efficient coaching alerts to advance the event of superhuman brokers. Current strategies usually derive reward fashions from human preferences, however human efficiency limitations constrain this course of. Relying on fastened reward fashions impedes the flexibility to boost studying throughout Large Language Model (LLM) coaching. Overcoming these challenges is essential for attaining breakthroughs in creating brokers with capabilities that surpass human efficiency.
Leveraging human desire information considerably enhances the flexibility of LLMs to observe directions successfully, as demonstrated by current research. Traditional Reinforcement Learning from Human Feedback (RLHF) entails studying a reward mannequin from human preferences, which is then fastened and employed for LLM coaching utilizing strategies like Proximal Policy Optimization (PPO). An rising different, Direct Preference Optimization (DPO), skips the reward mannequin coaching step, straight using human preferences for LLM coaching. However, each approaches face limitations tied to the size and high quality of obtainable human desire information, with RLHF moreover constrained by the frozen reward mannequin’s high quality.
Meta and New York University researchers have proposed a novel strategy known as Self-Rewarding Language Models, aiming to beat bottlenecks in conventional strategies. Unlike frozen reward fashions, their course of entails coaching a self-improving reward mannequin that is constantly up to date throughout LLM alignment. By integrating instruction-following and reward modeling right into a single system, the mannequin generates and evaluates its examples, refining instruction-following and reward modeling talents.
Self-Rewarding Language Models begin with a pretrained language mannequin and a restricted set of human-annotated information. The mannequin is designed to concurrently excel in two key expertise: i) instruction following and ii) self-instruction creation. The mannequin self-evaluates generated responses by means of the LLM-as-a-Judge mechanism, eliminating the necessity for an exterior reward mannequin. The iterative self-alignment course of entails growing new prompts, evaluating responses, and updating the mannequin utilizing AI Feedback Training. This strategy enhances instruction following and improves the mannequin’s reward modeling potential over successive iterations, deviating from conventional fastened reward fashions.

Self-Rewarding Language Models show vital enhancements in instruction following and reward modeling. Iterative coaching iterations present substantial efficiency good points, outperforming prior iterations and baseline fashions. The self-rewarding fashions exhibit aggressive efficiency on the AlpacaEval 2.0 leaderboard, surpassing present fashions (Claude 2, Gemini Pro, and GPT4) with proprietary alignment information. The technique’s effectiveness lies in its potential to iteratively improve instruction following and reward modeling, offering a promising avenue for self-improvement in language fashions. The mannequin’s coaching is demonstrated to be superior to different approaches that rely solely on constructive examples.
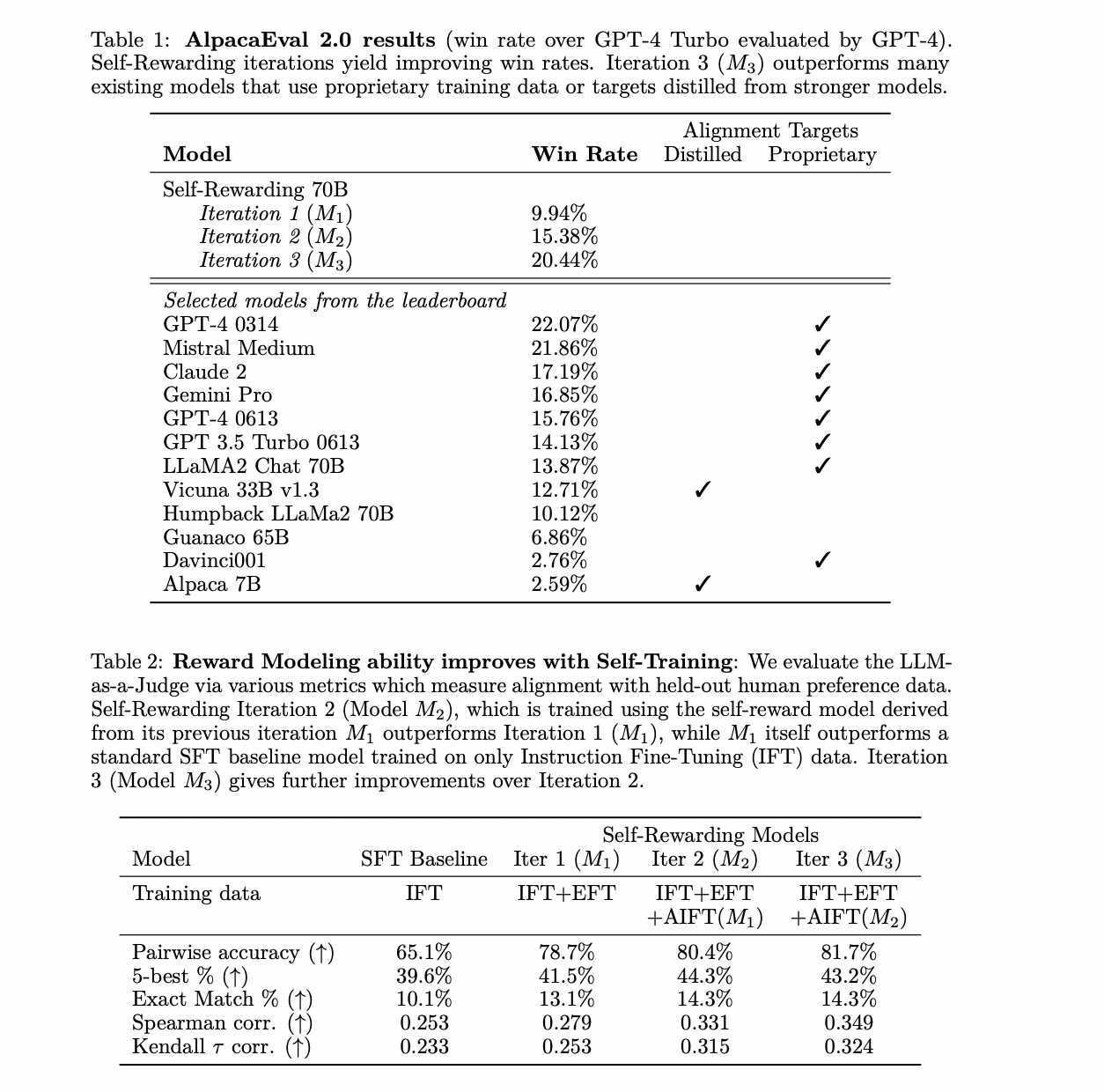
The researchers from Meta and New York University launched self-rewarding language fashions succesful of iterative self-alignment by producing and judging their coaching information. The mannequin assigns rewards to its generations by means of LLM-as-a-Judge prompting and Iterative DPO, enhancing each instruction-following and reward-modeling talents throughout iterations. While acknowledging the preliminary nature of the examine, the strategy presents an thrilling analysis avenue, suggesting continuous enchancment past conventional human-preference-based reward fashions in language mannequin coaching.
Check out the Paper. All credit score for this analysis goes to the researchers of this challenge. Also, don’t neglect to observe us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our e-newsletter..
Don’t Forget to hitch our Telegram Channel
![]()
Asjad is an intern advisor at Marktechpost. He is persuing B.Tech in mechanical engineering on the Indian Institute of Technology, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.