
")
In synthetic intelligence, the synergy between visible and textual information performs a pivotal function in evolving fashions able to understanding and producing content material that bridges the hole between these two modalities. Vision-Language Models (VLMs), which leverage huge datasets of paired photographs and textual content, are on the forefront of this revolutionary frontier. These fashions harness the ability of image-text datasets to realize breakthroughs in numerous duties, from enhancing picture recognition to pioneering new types of text-to-image synthesis.
The cornerstone of efficient VLMs lies within the high quality of the image-text datasets on which they’re educated. However, the duty of curating these datasets is fraught with challenges. While a wealthy supply of image-text pairs, the web additionally introduces a lot noise. Images usually include irrelevant or deceptive descriptions, complicating the coaching course of for fashions that depend on correct, well-aligned information. Earlier strategies like CLIPScore have tried to sort out this situation by measuring the alignment between photographs and texts. Despite their efforts, such strategies fail to handle the nuanced discrepancies inside these pairs, significantly with advanced photographs or prolonged descriptions that transcend easy object recognition.
A collaborative workforce from the University of California Santa Barbara and Bytedance has uniquely harnessed the capabilities of Multimodal Language Models (MLMs). Their answer focuses on filtering image-text information, a novel method that introduces a nuanced scoring system for information high quality analysis, providing a extra refined evaluation than its predecessors.
The methodology behind this groundbreaking work entails a subtle pipeline designed to generate high-quality instruction information for fine-tuning MLMs. The workforce recognized 4 vital metrics to guage the standard of image-text pairs: Image-Text Matching, Object Detail Fulfillment, Caption Text Quality, and Semantic Understanding. Each metric targets a particular facet of knowledge high quality, from the relevance and element of textual descriptions to the semantic richness they create to the accompanying photographs. This multi-faceted method ensures a complete evaluation, addressing the varied information high quality challenges in a approach that single-metric methods like CLIPScore can not.
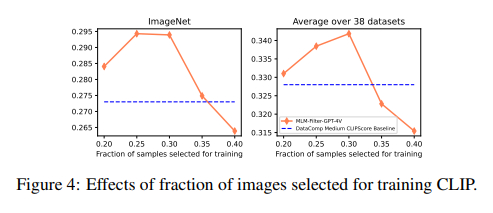
The analysis demonstrates important enhancements within the high quality of datasets ready for VLM coaching by way of rigorous testing and comparability with present filtering strategies. The MLM filter surpasses conventional strategies in aligning photographs with their textual counterparts and enhances the general efficacy of the inspiration fashions educated on these filtered datasets. This leap in efficiency is clear throughout numerous duties, showcasing the filter’s versatility and potential to function a common software in information curation.
In conclusion, the contributions of this analysis are manifold, presenting a leap ahead within the improvement of VLMs and the standard of multimodal datasets:
- A groundbreaking framework for fine-tuning MLMs to filter image-text information, considerably outperforming present strategies in information high quality evaluation.
- The analysis introduces a complete scoring system that evaluates the standard of image-text pairs throughout 4 distinct metrics. This method addresses the multifaceted nature of knowledge high quality in a approach that single-metric methods can not, offering a complete evaluation.
- The proposed MLM filter has demonstrated outstanding enhancements within the efficiency of VLMs educated on datasets. Through rigorous testing and comparability with present filtering strategies, the analysis showcases the filter’s potential to reinforce the general efficacy of the inspiration fashions, marking a important leap in efficiency.
Check out the Paper and Project. All credit score for this analysis goes to the researchers of this challenge. Also, don’t neglect to comply with us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our e-newsletter..
Don’t Forget to hitch our Telegram Channel
You can also like our FREE AI Courses….
![]()
Hello, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and quickly to be a administration trainee at American Express. I’m at present pursuing a twin diploma on the Indian Institute of Technology, Kharagpur. I’m enthusiastic about know-how and need to create new merchandise that make a distinction.