

In computational linguistics, a lot analysis focuses on how language fashions deal with and interpret intensive textual information. These fashions are essential for duties that require figuring out and extracting particular data from massive volumes of textual content, presenting a appreciable problem in guaranteeing accuracy and effectivity. A essential problem in processing intensive textual content information is the mannequin’s capacity to precisely establish and extract related data from huge content material swimming pools. This subject is especially pronounced in duties the place the mannequin must discern particular particulars from massive datasets or lengthy paperwork.
Existing analysis contains fashions like LLaMA, Yi, QWen, and Mistral, which make the most of superior consideration mechanisms to handle long-context data effectively. Techniques reminiscent of steady pretraining and sparse upcycling refine these fashions, enhancing their capacity to navigate intensive texts. CopyNet and Induction Head have laid foundational work by integrating coping mechanisms and in-context studying into sequence-to-sequence fashions. Moreover, the Needle-in-a-Haystack take a look at has been pivotal in benchmarking fashions’ precision in retrieving particular data inside massive datasets, shaping present methods in language mannequin improvement.
Researchers from Peking University, the University of Washington, MIT, UIUC, and the University of Edinburgh launched “retrieval heads,” specialised consideration mechanisms designed to reinforce data retrieval in transformer-based language fashions. These heads selectively concentrate on essential elements of in depth texts, a methodology distinguishing itself by focusing much less on normal consideration throughout your complete dataset and extra on focused environment friendly information retrieval. This focused method is especially efficient in dealing with long-context eventualities, setting it other than conventional fashions that always need assistance with large-scale information retrieval with out particular optimizations.
The methodology concerned conducting detailed experiments throughout a number of outstanding fashions reminiscent of LLaMA, Yi, QWen, and Mistral. Researchers utilized the Needle-in-a-Haystack take a look at, embedding particular items of data inside massive textual content blocks to measure the precision and effectiveness of retrieval heads. The research meticulously assessed the activation patterns of those heads below numerous experimental situations, together with completely different mannequin scales and fine-tuning states, to find out their affect on efficiency and error charges. This systematic testing helped set up a quantitative foundation for the importance of retrieval heads in enhancing accuracy and decreasing hallucinations in language processing duties.
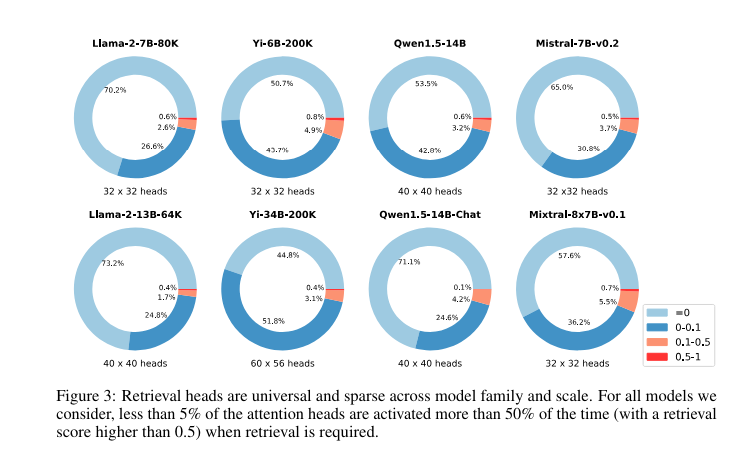
The outcomes revealed that fashions outfitted with retrieval heads considerably outperformed these with out in phrases of accuracy and effectivity. The Needle-in-a-Haystack checks, accuracy dropped from 94.7% to 63.6% when prime retrieval heads had been masked. Moreover, fashions with lively retrieval heads maintained excessive constancy to enter information, with error charges notably decrease than fashions the place these heads had been deactivated. This empirical information underscores the effectiveness of retrieval heads in enhancing the precision and reliability of data retrieval inside intensive textual content environments.
In conclusion, the analysis introduces and validates the idea of retrieval heads in transformer-based language fashions, demonstrating their pivotal function in enhancing data retrieval from intensive texts. The systematic testing throughout numerous fashions confirmed that retrieval heads considerably enhance accuracy and scale back errors. This discovery deepens our understanding of consideration mechanisms in large-scale textual content processing and suggests sensible enhancements for growing extra environment friendly and correct language fashions, doubtlessly benefiting a wide selection of purposes that depend on detailed and exact information extraction.
Check out the Paper and Github Page. All credit score for this analysis goes to the researchers of this mission. Also, don’t overlook to comply with us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our publication..
Don’t Forget to affix our 40k+ ML SubReddit
![]()
Nikhil is an intern advisor at Marktechpost. He is pursuing an built-in twin diploma in Materials on the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a sturdy background in Material Science, he’s exploring new developments and creating alternatives to contribute.