

Singing voice conversion (SVC) is an interesting area inside audio processing, aiming to remodel one singer’s voice into one other’s whereas preserving the track’s content material and melody intact. This expertise has broad purposes, from enhancing musical leisure to creative creation. A vital problem on this area has been the gradual processing speeds, particularly in diffusion-based SVC strategies. While producing high-quality and pure audio, these strategies are hindered by their prolonged, iterative sampling processes, making them much less appropriate for real-time purposes.
Various generative fashions have tried to deal with SVC’s challenges, together with autoregressive fashions, generative adversarial networks, normalizing circulate, and diffusion fashions. Each methodology makes an attempt to disentangle and encode singer-independent and singer-dependent options from audio knowledge, with various levels of success in audio high quality and processing effectivity.
The introduction of CoMoSVC, a brand new methodology developed by the Hong Kong University of Science and Technology and Microsoft Research Asia leveraging the consistency mannequin, marks a notable development in SVC. This strategy goals to obtain high-quality audio era and speedy sampling concurrently. At its core, CoMoSVC employs a diffusion-based instructor mannequin particularly designed for SVC and additional refines its course of by a scholar mannequin distilled underneath self-consistency properties. This innovation allows one-step sampling, a major leap ahead in addressing the gradual inference pace of conventional strategies.
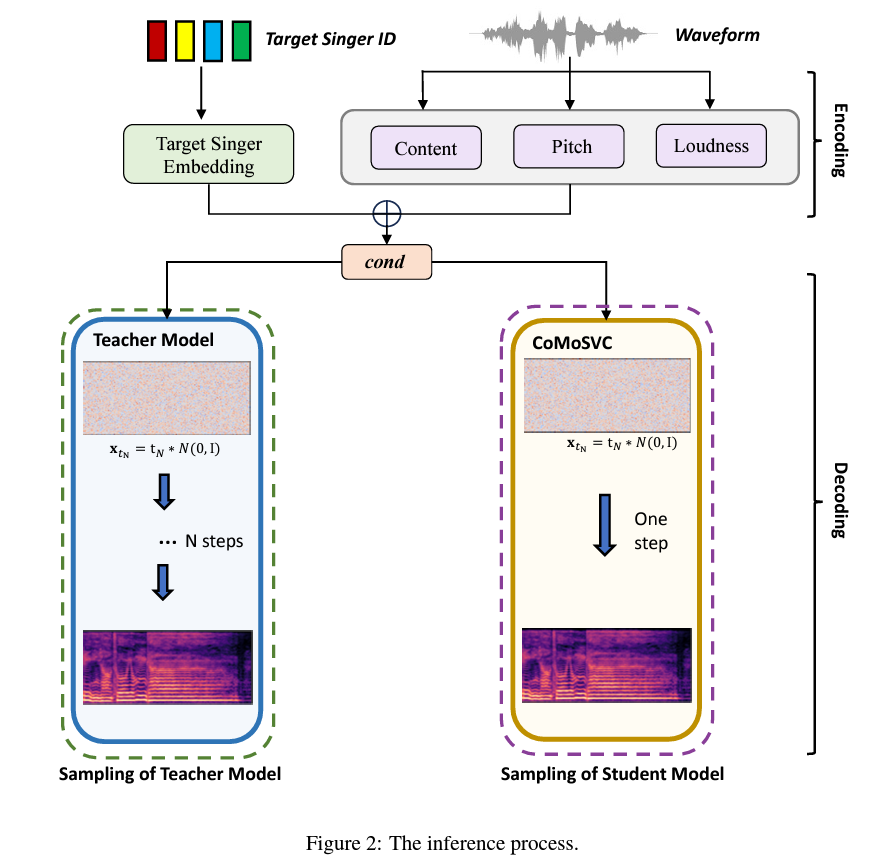
Delving deeper into the methodology, CoMoSVC operates by a two-stage course of: encoding and decoding. In the encoding stage, options are extracted from the waveform, and the singer’s id is encoded into embeddings. The decoding stage is the place CoMoSVC really innovates. It makes use of these embeddings to generate mel-spectrograms, subsequently rendered into audio. The standout characteristic of CoMoSVC is its scholar mannequin, distilled from a pre-trained instructor mannequin. This mannequin allows speedy, one-step audio sampling whereas preserving prime quality, a feat not achieved by earlier strategies.
In phrases of efficiency, CoMoSVC demonstrates exceptional outcomes. It considerably outpaces state-of-the-art diffusion-based SVC techniques in inference pace, up to 500 instances sooner. Yet, it maintains or surpasses their audio high quality and comparable efficiency. Objective and subjective evaluations of CoMoSVC reveal its capability to obtain comparable or superior conversion efficiency. This stability between pace and high quality makes CoMoSVC a groundbreaking growth in SVC expertise.
In conclusion, CoMoSVC is a major milestone in singing voice conversion expertise. It tackles the essential situation of gradual inference pace with out compromising audio high quality. By innovatively combining a teacher-student mannequin framework with the consistency mannequin, CoMoSVC units a brand new commonplace within the area, providing speedy and high-quality voice conversion that may revolutionize purposes in music leisure and past. This development solves a long-standing problem in SVC and opens up new prospects for real-time and environment friendly voice conversion purposes.
Check out the Paper and Project. All credit score for this analysis goes to the researchers of this venture. Also, don’t neglect to comply with us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our publication..
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a concentrate on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends superior technical data with sensible purposes. His present endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.