
 Tailored for a Range of Real-World Vision-Language Applications")
The improvement of multimodal massive language fashions (MLLMs) represents a vital leap ahead. These superior techniques, which combine language and visible processing, have broad functions, from picture captioning to seen query answering. However, a main problem has been the excessive computational sources these fashions sometimes require. Existing fashions, whereas highly effective, necessitate substantial sources for coaching and operation, limiting their sensible utility and adaptableness in numerous situations.
Researchers have made notable strides with fashions like LLaVA and MiniGPT-4, demonstrating spectacular capabilities in duties like picture captioning, visible query answering, and referring expression comprehension. However, these fashions should grapple with computational effectivity points regardless of their groundbreaking achievements. They demand vital sources, particularly through the coaching and inference levels, which poses a appreciable barrier to their widespread use, significantly in situations with restricted computational capabilities.
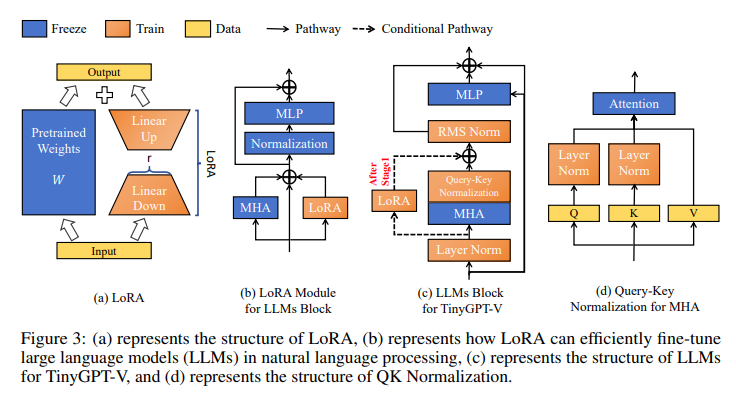
Addressing these limitations, researchers from Anhui Polytechnic University, Nanyang Technological University, and Lehigh University have launched TinyGPT-V, a mannequin designed to marry spectacular efficiency with decreased computational calls for. TinyGPT-V is distinct in its requirement of merely a 24G GPU for coaching and an 8G GPU or CPU for inference. It achieves this effectivity by leveraging the Phi-2 mannequin as its language spine and pre-trained imaginative and prescient modules from BLIP-2 or CLIP. The Phi-2 mannequin, recognized for its state-of-the-art efficiency amongst base language fashions with fewer than 13 billion parameters, supplies a stable basis for TinyGPT-V. This mixture permits TinyGPT-V to keep up excessive efficiency whereas considerably decreasing the computational sources required.
The structure of TinyGPT-V contains a distinctive quantization course of that makes it appropriate for native deployment and inference duties on gadgets with an 8G capability. This characteristic is especially helpful for sensible functions the place deploying large-scale fashions will not be possible. The mannequin’s construction additionally contains linear projection layers that embed visible options into the language mannequin, facilitating a extra environment friendly understanding of image-based info. These projection layers are initialized with a Gaussian distribution, bridging the hole between the visible and language modalities.
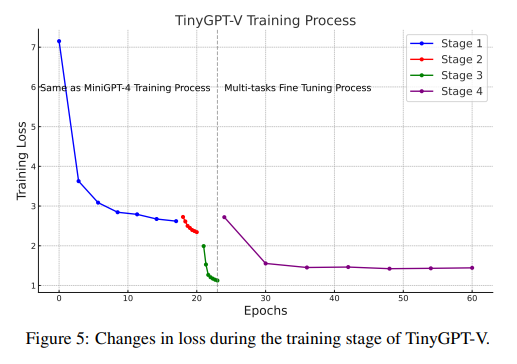
TinyGPT-V has demonstrated outstanding outcomes throughout a number of benchmarks, showcasing its capacity to compete with fashions of a lot bigger scales. In the Visual-Spatial Reasoning (VSR) zero-shot job, TinyGPT-V achieved the best rating, outperforming its counterparts with considerably extra parameters. Its efficiency in different benchmarks, reminiscent of GQA, IconVQ, VizWiz, and the Hateful Memes dataset, additional underscores its functionality to deal with complicated multimodal duties effectively. These outcomes spotlight TinyGPT-V’s excessive efficiency and computational effectivity steadiness, making it a viable possibility for numerous real-world functions.
In conclusion, the event of TinyGPT-V marks a vital development in MLLMs. Effective balancing of excessive efficiency with manageable computational calls for opens up new potentialities for making use of these fashions in situations the place useful resource constraints are vital. This innovation addresses the challenges in deploying MLLMs and paves the best way for their broader applicability, making them extra accessible and cost-effective for numerous makes use of.
Check out the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Also, don’t overlook to affix our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you want our work, you’ll love our publication..
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is obsessed with making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.