

Recent advances in large language models (LLMs) are very promising as mirrored of their functionality for common problem-solving in few-shot and zero-shot setups, even with out specific coaching on these duties. This is spectacular as a result of within the few-shot setup, LLMs are offered with just a few question-answer demonstrations previous to being given a check query. Even tougher is the zero-shot setup, the place the LLM is instantly prompted with the check query solely.
Even although the few-shot setup has dramatically decreased the quantity of information required to adapt a mannequin for a selected use-case, there are nonetheless circumstances the place producing pattern prompts may be difficult. For instance, handcrafting even a small quantity of demos for the broad vary of duties coated by general-purpose models may be tough or, for unseen duties, unimaginable. For instance, for duties like summarization of lengthy articles or those who require area data (e.g., medical query answering), it may be difficult to generate pattern solutions. In such conditions, models with excessive zero-shot efficiency are helpful since no guide immediate technology is required. However, zero-shot efficiency is often weaker because the LLM will not be offered with steerage and thus is susceptible to spurious output.
In “Better Zero-shot Reasoning with Self-Adaptive Prompting”, printed at ACL 2023, we suggest Consistency-Based Self-Adaptive Prompting (COSP) to deal with this dilemma. COSP is a zero-shot automated prompting methodology for reasoning issues that fastidiously selects and constructs pseudo-demonstrations for LLMs utilizing solely unlabeled samples (which might be sometimes straightforward to acquire) and the models’ personal predictions. With COSP, we largely shut the efficiency hole between zero-shot and few-shot whereas retaining the fascinating generality of zero-shot prompting. We comply with this with “Universal Self-Adaptive Prompting“ (USP), accepted at EMNLP 2023, wherein we lengthen the concept to a variety of common pure language understanding (NLU) and pure language technology (NLG) duties and show its effectiveness.
Prompting LLMs with their very own outputs
Knowing that LLMs profit from demonstrations and have a minimum of some zero-shot talents, we puzzled whether or not the mannequin’s zero-shot outputs may function demonstrations for the mannequin to immediate itself. The problem is that zero-shot options are imperfect, and we danger giving LLMs poor high quality demonstrations, which might be worse than no demonstrations in any respect. Indeed, the determine under exhibits that including an accurate demonstration to a query can result in an accurate resolution of the check query (Demo1 with query), whereas including an incorrect demonstration (Demo 2 + questions, Demo 3 with questions) results in incorrect solutions. Therefore, we have to choose dependable self-generated demonstrations.
 |
| Example inputs & outputs for reasoning duties, which illustrates the necessity for fastidiously designed choice process for in-context demonstrations (MultiArith dataset & PaLM-62B mannequin): (1) zero-shot chain-of-thought with no demo: appropriate logic however unsuitable reply; (2) appropriate demo (Demo1) and proper reply; (3) appropriate however repetitive demo (Demo2) results in repetitive outputs; (4) faulty demo (Demo3) results in a unsuitable reply; however (5) combining Demo3 and Demo1 once more results in an accurate reply. |
COSP leverages a key statement of LLMs: that assured and constant predictions are extra seemingly appropriate. This statement, of course, is dependent upon how good the uncertainty estimate of the LLM is. Luckily, in large models, earlier works recommend that the uncertainty estimates are sturdy. Since measuring confidence requires solely mannequin predictions, not labels, we suggest to make use of this as a zero-shot proxy of correctness. The high-confidence outputs and their inputs are then used as pseudo-demonstrations.
With this as our beginning premise, we estimate the mannequin’s confidence in its output based mostly on its self-consistency and use this measure to pick out sturdy self-generated demonstrations. We ask LLMs the identical query a number of instances with zero-shot chain-of-thought (CoT) prompting. To information the mannequin to generate a variety of potential rationales and ultimate solutions, we embody randomness managed by a “temperature” hyperparameter. In an excessive case, if the mannequin is 100% sure, it ought to output equivalent ultimate solutions every time. We then compute the entropy of the solutions to gauge the uncertainty — the solutions which have excessive self-consistency and for which the LLM is extra sure, are more likely to be appropriate and shall be chosen.
Assuming that we are offered with a set of unlabeled questions, the COSP methodology is:
- Input every unlabeled query into an LLM, acquiring a number of rationales and solutions by sampling the mannequin a number of instances. The most frequent solutions are highlighted, adopted by a rating that measures consistency of solutions throughout a number of sampled outputs (larger is healthier). In addition to favoring extra constant solutions, we additionally penalize repetition inside a response (i.e., with repeated phrases or phrases) and encourage range of chosen demonstrations. We encode the choice in the direction of constant, un-repetitive and various outputs within the type of a scoring perform that consists of a weighted sum of the three scores for choice of the self-generated pseudo-demonstrations.
- We concatenate the pseudo-demonstrations into check questions, feed them to the LLM, and procure a ultimate predicted reply.
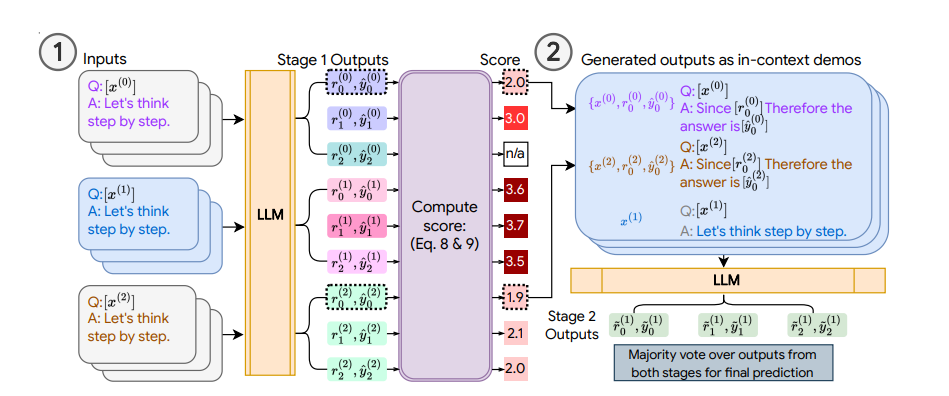 |
| Illustration of COSP: In Stage 1 (left), we run zero-shot CoT a number of instances to generate a pool of demonstrations (every consisting of the query, generated rationale and prediction) and assign a rating. In Stage 2 (proper), we increase the present check query with pseudo-demos (blue packing containers) and question the LLM once more. A majority vote over outputs from each phases types the ultimate prediction. |
COSP focuses on question-answering duties with CoT prompting for which it’s straightforward to measure self-consistency because the questions have distinctive appropriate solutions. But this may be tough for different duties, akin to open-ended question-answering or generative duties that don’t have distinctive solutions (e.g., textual content summarization). To tackle this limitation, we introduce USP wherein we generalize our strategy to different common NLP duties:
- Classification (CLS): Problems the place we will compute the likelihood of every class utilizing the neural community output logits of every class. In this fashion, we will measure the uncertainty with out a number of sampling by computing the entropy of the logit distribution.
- Short-form technology (SFG): Problems like query answering the place we will use the identical process talked about above for COSP, however, if needed, with out the rationale-generating step.
- Long-form technology (LFG): Problems like summarization and translation, the place the questions are sometimes open-ended and the outputs are unlikely to be equivalent, even when the LLM is definite. In this case, we use an overlap metric wherein we compute the typical of the pairwise ROUGE rating between the totally different outputs to the identical question.
 |
| Illustration of USP in exemplary duties (classification, QA and textual content summarization). Similar to COSP, the LLM first generates predictions on an unlabeled dataset whose outputs are scored with logit entropy, consistency or alignment, relying on the duty sort, and pseudo-demonstrations are chosen from these input-output pairs. In Stage 2, the check situations are augmented with pseudo-demos for prediction. |
We compute the related confidence scores relying on the kind of process on the aforementioned set of unlabeled check samples. After scoring, just like COSP, we choose the assured, various and fewer repetitive solutions to type a model-generated pseudo-demonstration set. We lastly question the LLM once more in a few-shot format with these pseudo-demonstrations to acquire the ultimate predictions on all the check set.
Key Results
For COSP, we deal with a set of six arithmetic and commonsense reasoning issues, and we evaluate in opposition to 0-shot-CoT (i.e., “Let’s assume step-by-step“ solely). We use self-consistency in all baselines in order that they use roughly the identical quantity of computational sources as COSP. Compared throughout three LLMs, we see that zero-shot COSP considerably outperforms the usual zero-shot baseline.
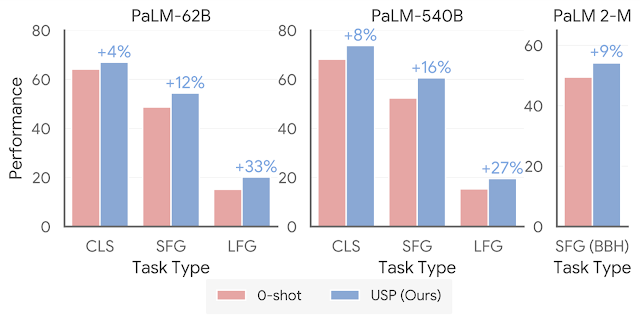 |
| USP improves considerably on 0-shot efficiency. “CLS” is a median of 15 classification duties; “SFG” is the typical of 5 short-form technology duties; “LFG” is the typical of two summarization duties. “SFG (BBH)” is a median of all BIG-Bench Hard duties, the place every query is in SFG format. |
For USP, we increase our evaluation to a a lot wider vary of duties, together with greater than 25 classifications, short-form technology, and long-form technology duties. Using the state-of-the-art PaLM 2 models, we additionally check in opposition to the BIG-Bench Hard suite of duties the place LLMs have beforehand underperformed in comparison with folks. We present that in all circumstances, USP once more outperforms the baselines and is aggressive to prompting with golden examples.
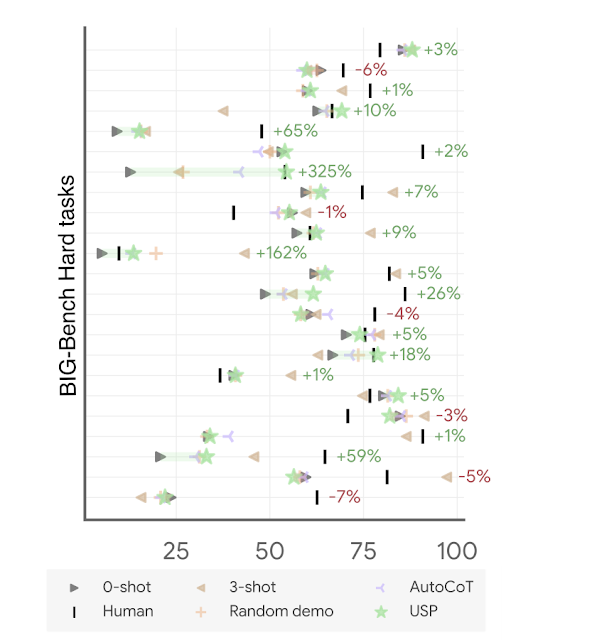 |
| Accuracy on BIG-Bench Hard duties with PaLM 2-M (every line represents a process of the suite). The acquire/loss of USP (inexperienced stars) over customary 0-shot (inexperienced triangles) is proven in percentages. “Human” refers to common human efficiency; “AutoCoT” and “Random demo” are baselines we in contrast in opposition to within the paper; and “3-shot” is the few-shot efficiency for 3 handcrafted demos in CoT format. |
We additionally analyze the working mechanism of USP by validating the important thing statement above on the relation between confidence and correctness, and we discovered that in an awesome majority of the circumstances, USP picks assured predictions which might be extra seemingly higher in all process sorts thought of, as proven within the determine under.
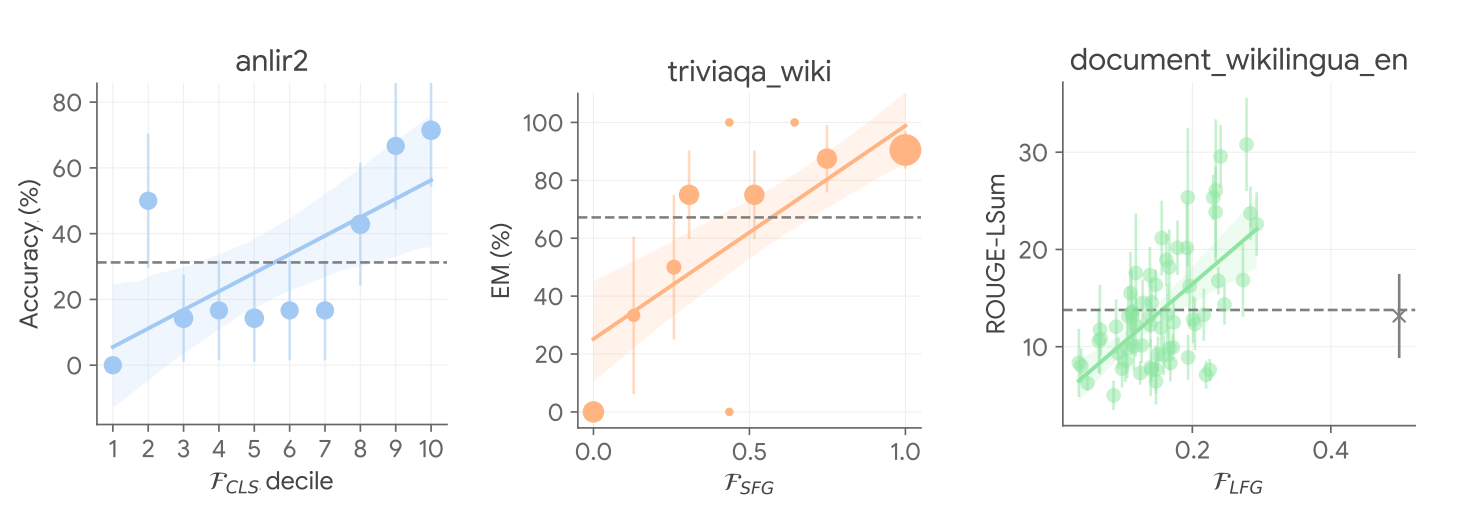 |
| USP picks assured predictions which might be extra seemingly higher. Ground-truth efficiency metrics in opposition to USP confidence scores in chosen duties in varied process sorts (blue: CLS, orange: SFG, inexperienced: LFG) with PaLM-540B. |
Conclusion
Zero-shot inference is a extremely sought-after functionality of fashionable LLMs, but the success wherein poses distinctive challenges. We suggest COSP and USP, a household of versatile, zero-shot automated prompting strategies relevant to a variety of duties. We present large enchancment over the state-of-the-art baselines over quite a few process and mannequin mixtures.
Acknowledgements
This work was carried out by Xingchen Wan, Ruoxi Sun, Hootan Nakhost, Hanjun Dai, Julian Martin Eisenschlos, Sercan Ö. Arık, and Tomas Pfister. We wish to thank Jinsung Yoon Xuezhi Wang for offering useful opinions, and different colleagues at Google Cloud AI Research for his or her dialogue and suggestions.