

With the rise of language fashions, there was an infinite concentrate on enhancing the educational of LMs to speed up the educational velocity and obtain a sure mannequin efficiency with as few coaching steps as attainable. This emphasis aids people in understanding the boundaries of LMs amidst their escalating computational necessities. It additionally advances the democratization of huge language fashions (LLMs), benefiting analysis and business communities.
Prior works like Pre-Trained Models, Past, Present, and Future, concentrate on designing efficient architectures, using wealthy contexts, and enhancing computational effectivity. In h2oGPT: Democratizing Large Language Models, the researchers have tried to create open-source alternate options to the closed-source approaches. In Large Batch Optimization for Deep Learning: Training BERT in 76 minutes, they tried to overcome the computational problem of LLMs. These prior works discover sensible acceleration strategies on the mannequin, optimizer, or knowledge ranges.
The researchers from the CoAI Group, Tsinghua University, and Microsoft Research have proposed a principle for optimizing LM studying, starting with maximizing the info compression ratio. They derive the Learning Law theorem to elucidate optimum studying dynamics. Validation experiments on linear classification and language modeling duties affirm the concept’s properties. Results point out that optimum LM studying enhances coefficients in LM scaling legal guidelines, providing promising implications for sensible studying acceleration strategies.
In their technique (Optimal Learning of Language Models), the researchers demonstrated the rules of optimizing the LM studying velocity, together with the optimization goal, the property of optimum studying dynamics, and the important enchancment of the educational acceleration. For the optimization goal, they’ve proposed to reduce the world underneath the curve (AUC), a studying course of with the smallest loss AUC corresponds to the very best compression ratio. Then, they derived the Learning Law theorem that characterizes the property of dynamics in the LM studying course of that achieves the optimum of their goal. Here, a studying coverage induces a studying course of that determines which knowledge factors the LM learns because the coaching progresses.
After conducting experiments on linear classification with Perceptron and language modeling with Transformer, researchers optimized studying insurance policies and validated them empirically. Near-optimal insurance policies considerably accelerated studying, enhancing loss AUC by 5.50× and 2.41× for Perceptron and Transformer, respectively. Results confirmed theoretical predictions, demonstrating improved scaling regulation coefficients by up to 96.6% and 21.2%, promising sooner LM coaching with sensible significance.
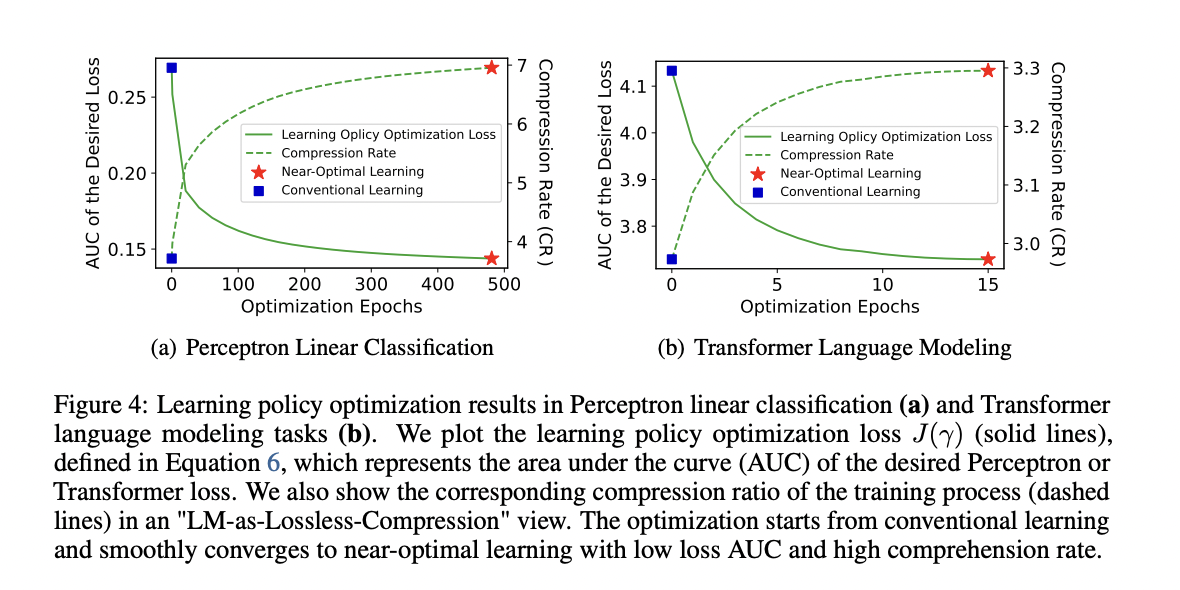
In conclusion, researchers from the CoAI Group, Tsinghua University, and Microsoft Research have proposed a principle for optimizing LM studying to maximize compression ratio. They derive the Learning Law theorem, confirming that every one examples contribute equally to optimum studying, validated in experiments. The optimum course of improves LM scaling regulation coefficients, guiding future acceleration strategies.
Check out the Paper and Github. All credit score for this analysis goes to the researchers of this mission. Also, don’t neglect to observe us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you want our work, you’ll love our e-newsletter..
Don’t Forget to be part of our Telegram Channel
You may like our FREE AI Courses….
![]()
Asjad is an intern marketing consultant at Marktechpost. He is persuing B.Tech in mechanical engineering on the Indian Institute of Technology, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.