

The basic rigidity in conversational AI has at all times been a binary selection: reply quick or reply sensible. Real-time speech-to-speech (S2S) fashions — the type that energy natural-feeling voice assistants — begin speaking nearly immediately, however their solutions are typically shallow. Cascaded programs that route speech by way of a big language mannequin (LLM) are much more educated, however the pipeline delay is lengthy sufficient to make dialog really feel stilted and robotic. Researchers at Sakana AI, the Tokyo-based AI lab introduces KAME (Knowledge-Access Model Extension), a hybrid structure that retains the near-zero response latency of a direct S2S system whereas injecting the richer data of a back-end LLM in actual time.
The Problem: Two Paradigms, Two Tradeoffs
To perceive why KAME is vital, it helps to grasp the 2 dominant designs it bridges.
A direct S2S mannequin like Moshi (developed by KyutAI) is a monolithic transformer that takes in audio tokens and produces audio tokens in a steady loop. Because it doesn’t must synchronize with exterior programs, its response latency is exceptionally low — for a lot of queries, the mannequin begins talking earlier than the consumer even finishes their query. But as a result of acoustic indicators are far information-denser than textual content, the mannequin has to spend vital capability modeling paralinguistic options like tone, emotion, and rhythm. That leaves much less room for factual data and deep reasoning.

A cascaded system, in contrast, routes the consumer’s speech by way of an Automatic Speech Recognition (ASR) mannequin, feeds the ensuing textual content into a robust LLM, after which converts the LLM’s response again into speech by way of a Text-to-Speech (TTS) engine. The data high quality is great — you’ll be able to plug in any frontier LLM — however the system should anticipate the consumer to complete talking earlier than ASR and LLM processing may even start. The result’s a median latency of round 2.1 seconds, which is lengthy sufficient to noticeably interrupt pure conversational stream.
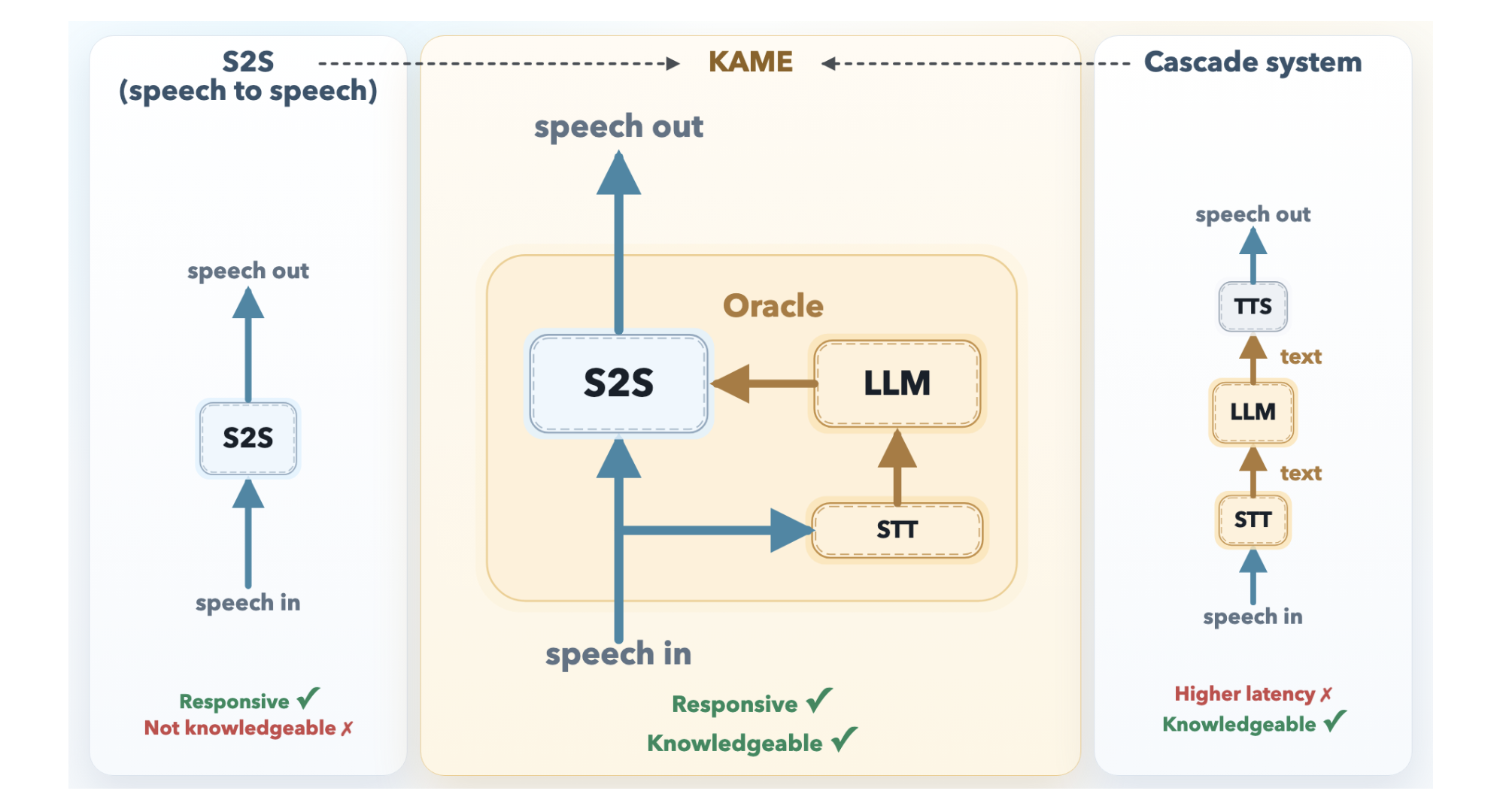
KAME’s Architecture: Speaking While Thinking
KAME operates as a tandem system with two asynchronous parts operating in parallel.
The front-end S2S module is predicated on the Moshi structure and processes audio in actual time on the cycle of discrete audio tokens (roughly each 80 milliseconds). It begins producing a spoken response instantly. Internally, Moshi’s authentic three-stream design — enter audio, internal monologue (textual content), and output audio — is prolonged in KAME with a fourth stream: the oracle stream. This is the important thing innovation level.
The back-end LLM module consists of a streaming speech-to-text (STT) element paired with a full-scale LLM. As the consumer speaks, the STT element repeatedly builds a partial transcript and periodically sends it to the back-end LLM. For every partial transcript it receives, the LLM generates a candidate textual content response — referred to as an oracle — and streams it again to the front-end. Because the consumer’s speech remains to be arriving, these oracles begin as educated guesses and grow to be progressively extra correct because the transcript grows extra full.
The front-end S2S transformer then situations its ongoing speech output on each its personal inside context and these incoming oracle tokens. When a brand new, higher oracle arrives, the mannequin can right course — successfully updating its response mid-sentence, the way in which a human may. Because each modules run asynchronously and independently, the preliminary response latency stays close to zero.
Training on Simulated Oracles
One problem is that no naturally occurring dataset accommodates oracle indicators. Sakana AI analysis group addresses this with a method referred to as Simulated Oracle Augmentation. Using a ‘simulator’ LLM and an ordinary conversational dataset (consumer utterance + ground-truth response), the analysis group generates artificial oracle sequences that mimic what a real-time LLM would produce throughout totally different ranges of transcript completeness. They outline six trace ranges (0–5), starting from a totally unguided guess at trace degree 0 to the verbatim ground-truth response at trace degree 5. The coaching knowledge for KAME was constructed from 56,582 artificial dialogues drawn from MMLU-Pro, GSM8K, and HSSBench, transformed to audio by way of TTS and augmented with these progressive oracle sequences.
Results: Near-Cascaded Quality, Near-Zero Latency
Evaluations on a speech-synthesized subset of the MT-Bench multi-turn Q&A benchmark — particularly the reasoning, STEM, and humanities classes (Coding, Extraction, Math, Roleplay, and Writing had been excluded as unsuitable for speech interplay) — present a dramatic enchancment. Moshi alone scores 2.05 on common. KAME with gpt-4.1 because the back-end scores 6.43, and KAME with claude-opus-4-1 because the back-end scores 6.23 — each at primarily the identical latency as Moshi. The main cascaded system, Unmute (additionally backed by gpt-4.1), scores 7.70, however with a median latency of two.1 seconds versus near-zero for KAME.
To isolate back-end functionality from timing results, the analysis group additionally evaluated the back-end LLM’s textual content responses from the ultimate oracle injection in every KAME session instantly — bypassing the premature-generation downside fully. Those scores averaged 7.79 (reasoning 6.48, STEM 8.34, humanities 8.56), similar to Unmute’s 7.70. This confirms that KAME’s hole to cascaded programs is just not a ceiling on the back-end LLM’s data, however a consequence of beginning to communicate earlier than the complete consumer question has been heard.
Crucially, KAME is totally back-end agnostic. The front-end was skilled utilizing gpt-4.1-nano as the first back-end, however swapping in claude-opus-4-1 or gemini-2.5-flash at inference time requires no retraining. In Sakana AI’s experiments, claude-opus-4-1 tended to outperform gpt-4.1 on reasoning duties, whereas gpt-4.1 scored greater on humanities questions — suggesting practitioners can route queries to probably the most task-appropriate LLM with out touching the front-end mannequin.
Key Takeaways
- KAME bridges the speed-vs-knowledge tradeoff in conversational AI by operating a front-end speech-to-speech mannequin and a back-end LLM asynchronously in parallel — the S2S mannequin responds instantly whereas the LLM repeatedly injects progressively refined ‘oracle’ indicators in actual time, shifting the paradigm from ‘think, then speak’ to ‘speak while thinking.’
- The efficiency good points are substantial with none latency value — KAME raises the MT-Bench rating from 2.05 (Moshi baseline) to six.43, approaching the cascaded system Unmute’s 7.70, whereas sustaining near-zero median response latency versus Unmute’s 2.1 seconds.
- The structure is totally back-end agnostic — the front-end was skilled utilizing gpt-4.1-nano however helps plug-and-play swapping of any frontier LLM (gpt-4.1, claude-opus-4-1, gemini-2.5-flash) at inference time with no retraining, enabling task-specific LLM choice primarily based on area strengths.
Check out the Model Weights, Paper, Inference code and Technical particulars. Also, be at liberty to observe us on Twitter and don’t neglect to affix our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.
ztoog