
Everyone talks about LLMs—however in the present day’s AI ecosystem is much greater than simply language fashions. Behind the scenes, a complete household of specialised architectures is quietly remodeling how machines see, plan, act, section, characterize ideas, and even run effectively on small gadgets. Each of those fashions solves a distinct a part of the intelligence puzzle, and collectively they’re shaping the following technology of AI programs.
In this text, we’ll discover the 5 main gamers: Large Language Models (LLMs), Vision-Language Models (VLMs), Mixture of Experts (MoE), Large Action Models (LAMs) & Small Language Models (SLMs).
Large Language Models (LLMs)
LLMs soak up textual content, break it into tokens, flip these tokens into embeddings, go them via layers of transformers, and generate textual content again out. Models like ChatGPT, Claude, Gemini, Llama, and others all comply with this fundamental course of.
At their core, LLMs are deep studying fashions educated on huge quantities of textual content knowledge. This coaching permits them to grasp language, generate responses, summarize data, write code, reply questions, and carry out a variety of duties. They use the transformer structure, which is extraordinarily good at dealing with lengthy sequences and capturing advanced patterns in language.
Today, LLMs are extensively accessible via shopper instruments and assistants—from OpenAI’s ChatGPT and Anthropic’s Claude to Meta’s Llama fashions, Microsoft Copilot, and Google’s Gemini and BERT/PaLM household. They’ve grow to be the muse of recent AI functions due to their versatility and ease of use.

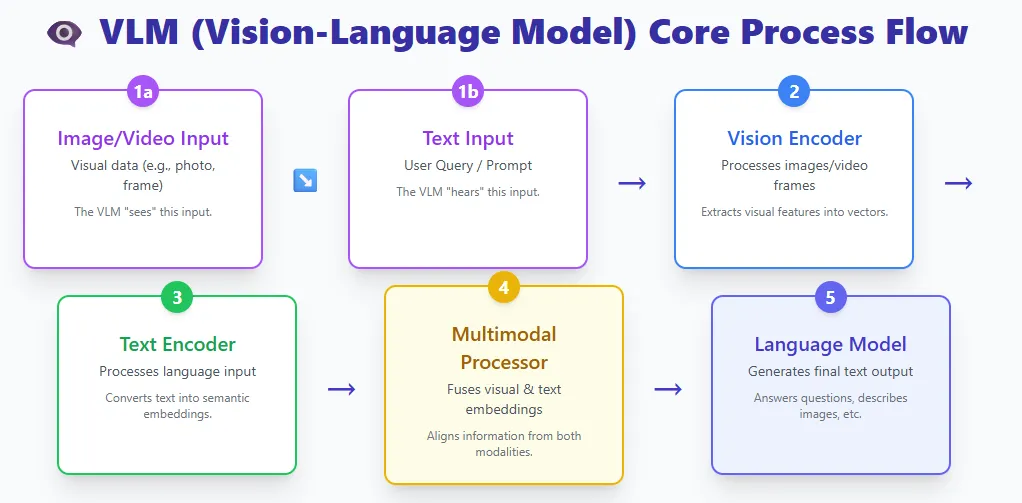
Vision-Language Models (VLMs)
VLMs mix two worlds:
- A imaginative and prescient encoder that processes photographs or video
- A textual content encoder that processes language
Both streams meet in a multimodal processor, and a language mannequin generates the ultimate output.
Examples embody GPT-4V, Gemini Pro Vision, and LLaVA.
A VLM is actually a big language mannequin that has been given the flexibility to see. By fusing visible and textual content representations, these fashions can perceive photographs, interpret paperwork, reply questions on footage, describe movies, and extra.
Traditional pc imaginative and prescient fashions are educated for one slender process—like classifying cats vs. canines or extracting textual content from a picture—they usually can’t generalize past their coaching courses. If you want a brand new class or process, you have to retrain them from scratch.
VLMs take away this limitation. Trained on big datasets of photographs, movies, and textual content, they’ll carry out many imaginative and prescient duties zero-shot, just by following pure language directions. They can do all the things from picture captioning and OCR to visible reasoning and multi-step doc understanding—all with out task-specific retraining.
This flexibility makes VLMs some of the highly effective advances in fashionable AI.
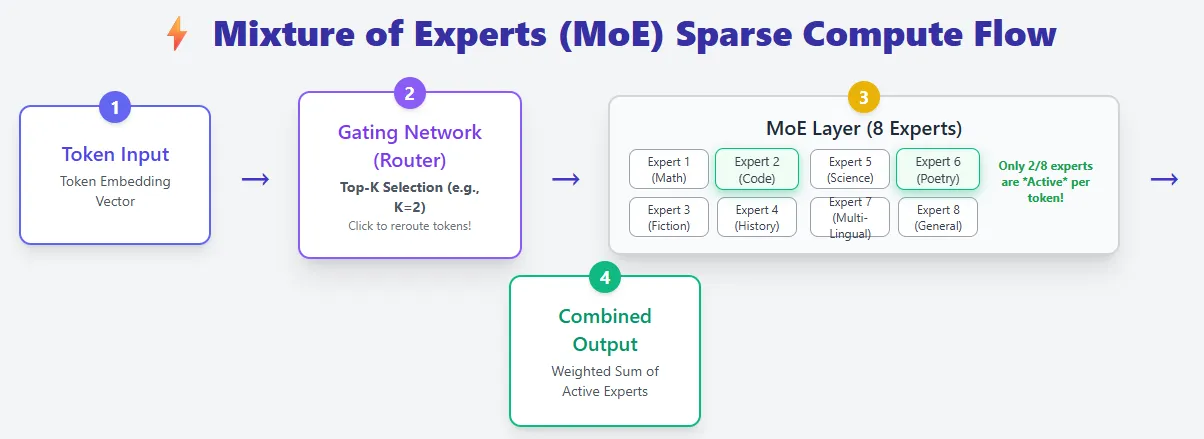
Mixture of Experts (MoE)
Mixture of Experts fashions construct on the usual transformer structure however introduce a key improve: as an alternative of 1 feed-forward community per layer, they use many smaller skilled networks and activate only some for every token. This makes MoE fashions extraordinarily environment friendly whereas providing huge capability.
In a daily transformer, each token flows via the identical feed-forward community, which means all parameters are used for each token. MoE layers exchange this with a pool of specialists, and a router decides which specialists ought to course of every token (Top-Ok choice). As a outcome, MoE fashions could have way more complete parameters, however they solely compute with a small fraction of them at a time—giving sparse compute.
For instance, Mixtral 8×7B has 46B+ parameters, but every token makes use of solely about 13B.
This design drastically reduces inference price. Instead of scaling by making the mannequin deeper or wider (which will increase FLOPs), MoE fashions scale by including extra specialists, boosting capability with out elevating per-token compute. This is why MoEs are sometimes described as having “bigger brains at lower runtime cost.”
Large Action Models (LAMs)
Large Action Models go a step past producing textual content—they flip intent into motion. Instead of simply answering questions, a LAM can perceive what a consumer needs, break the duty into steps, plan the required actions, after which execute them in the actual world or on a pc.
A typical LAM pipeline contains:
- Perception – Understanding the consumer’s enter
- Intent recognition – Identifying what the consumer is attempting to realize
- Task decomposition – Breaking the aim into actionable steps
- Action planning + reminiscence – Choosing the best sequence of actions utilizing previous and current context
- Execution – Carrying out duties autonomously
Examples embody Rabbit R1, Microsoft’s UFO framework, and Claude Computer Use, all of which might function apps, navigate interfaces, or full duties on behalf of a consumer.
LAMs are educated on huge datasets of actual consumer actions, giving them the flexibility to not simply reply, however act—reserving rooms, filling varieties, organizing recordsdata, or performing multi-step workflows. This shifts AI from a passive assistant into an energetic agent able to advanced, real-time decision-making.
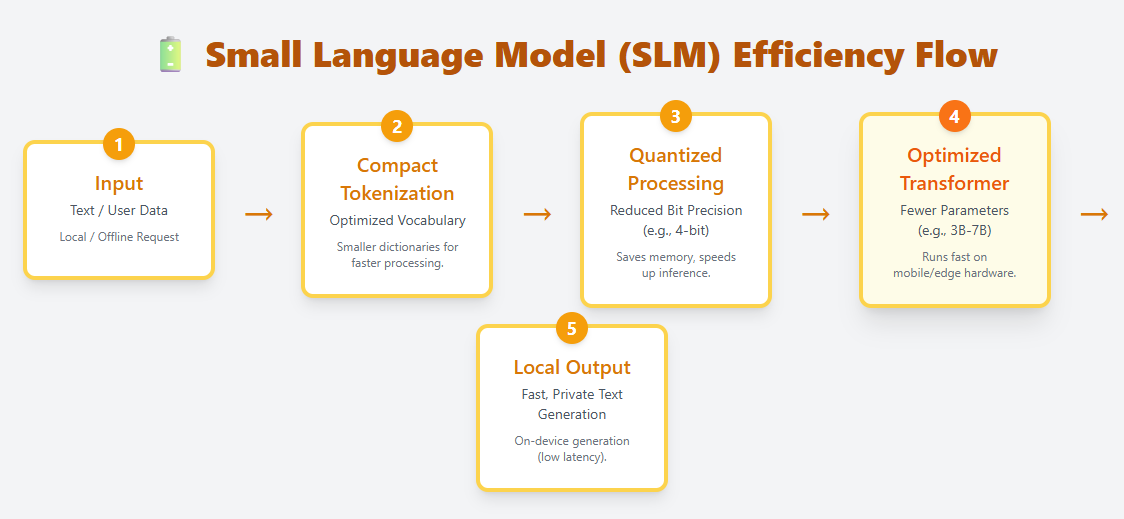
Small Language Models (SLMs)
SLMs are light-weight language fashions designed to run effectively on edge gadgets, cell {hardware}, and different resource-constrained environments. They use compact tokenization, optimized transformer layers, and aggressive quantization to make native, on-device deployment attainable. Examples embody Phi-3, Gemma, Mistral 7B, and Llama 3.2 1B.
Unlike LLMs, which can have a whole bunch of billions of parameters, SLMs sometimes vary from just a few million to a couple billion. Despite their smaller dimension, they’ll nonetheless perceive and generate pure language, making them helpful for chat, summarization, translation, and process automation—while not having cloud computation.
Because they require far much less reminiscence and compute, SLMs are perfect for:
- Mobile apps
- IoT and edge gadgets
- Offline or privacy-sensitive eventualities
- Low-latency functions the place cloud calls are too gradual
SLMs characterize a rising shift towards quick, non-public, and cost-efficient AI, bringing language intelligence immediately onto private gadgets.
ZTOOG.COM